 S, orR>P>S
S, orR>P>S | This is a file in the archives of the Stanford Encyclopedia of Philosophy. |
The
"dilemma" faced by the prisoners here is that, whatever the other
does, each is better off confessing than remaining silent. But the
outcome obtained when both confess is worse for each than the outcome
they would have obtained had both remained silent. A common view is
that the puzzle illustrates a failure of individual
The sections below provide a variety of more precise characterizations of the prisoner's dilemma, beginning with the narrowest. `Prisoner's dilemma' is abbreviated as `PD'. Future editions of the entry will also survey some applications in philosophy, and attempts to "solve" the PD by showing that remaining silent is individually rational after all.
| C | D | |
| C | R,R | S,T |
| D | T,S | P,P |
satisfying the following chain of inequalities:
| PD1) | T>R>P>S |
There are two players, Row and Column. Each has two possible moves, "cooperate" or "defect," corresponding, respectively, to the options of remaining silent or confessing in the illustrative anecdote above. For each possible pair of moves, the payoffs to Row and Column (in that order) are listed in the appropriate cell. R is the "reward" payoff that each player receives if both cooperate. P is the "punishment" that each receives if both defect. T is the "temptation" that each receives if he alone defects and S is the "sucker" payoff that he receives if he alone cooperates. We assume here that the game is symmetric, i.e., that the reward, punishment, temptation or sucker payoff is the same for each player, and payoffs have only ordinal significance, i.e., they indicate whether one payoff is better than another, but tell us nothing about how much better. It is now easy to see that we have the structure of a dilemma like the one in the story. Suppose Column cooperates. Then Row gets R for cooperating and T for defecting, and so is better off defecting. Suppose Column defects. Then Row gets S for cooperating and P for defecting, and so is again better off defecting. The move D for Row is said to strictly dominate the move C: whatever his opponent does, he is better off choosing D than C. By symmetry D also strictly dominates C for Column. Thus two "rational" players will defect and receive a payoff of P, while two "irrational" players can cooperate and receive greater payoff R. In standard treatments, game theory assumes rationality and common knowledge. Each player is rational, knows the other is rational, knows that the other knows he is rational, etc. Each player also knows how the other values the outcomes. But since D strictly dominates C for both players, the argument for dilemma here requires only that each player knows his own payoffs. (The argument remains valid, of course, under the stronger standard assumptions.) It is also worth noting that the outcome (D,D) of both players defecting is the game's only strong nash equilibrium, i.e., it is the only outcome from which each player could only do worse by unilaterally changing its move. Flood and Dresher's interest in their dilemma seems to have stemmed from their view that it provided a counterexample to the claim that the nash equilibria of a game constitute its natural "solutions".
If there can be "ties" in rankings of the payoffs, condition PD1 can be weakened without destroying the nature of the dilemma. For suppose that one of the following conditions obtain:
| PD2) | T>R>PS, or |
|||
| TR>P>S |
||||
Then, for each player, although D does not strictly dominate C, it still weakly dominates in the sense that each player always does at least as well, and sometimes better, by playing C. Under these conditions it still seems rational to play D, which again results in the payoff that neither player prefers. Let us call a game that meets PD2 a weak PD. Note that in a weak PD that does not satisfy PD1 mutual defection is no longer a nash equilibrium in the sense defined above. It is still, however, the only equilibrium in the weaker sense, that neither player can improve its position by unilaterally changing its move. Again, one might suppose that if there is a unique equilibrium of this weaker variety, rational self-interested players would reach it.
| C | D | |
| C | Rr,Rc | Sr,Tc |
| D | Tr,Sc | Pr,Pc |
If we assume that the payoffs are ordered as before for each player, i.e., that Ti>Ri>Pi>Si when i=r,c, then, as before, D is the strictly dominant move for both players, but the outcome (D,D) of both players making this move is worse for each than (C,C). The force of the dilemma can now also be felt under weaker conditions, however. Consider the following three pairs of inequalities:
| PD3) a. | Tr>Rr and Pr>Sr | ||||
| b. | Tc>Rc and Pc>Sc | ||||
| c. | Rr>Pr and Rc>Pc | ||||
If these conditions all obtain the argument for dilemma goes through
as before. Defection strictly dominates cooperation for each player,
and (C,C) is strictly preferred by each to
(D,D). If one of the two > signs in each of the
conditions a - c is replaced by a weak inequality sign
we have a weak PD. D weakly dominates C for each player
(i.e., D is as good as C in all cases and better in
some) and (C,C) weakly better than (D,D)
(i.e., it is at least as good for both players and better for
one). Since none of the clauses requires comparisons between r's
payoffs and c's, we need not assume that > has any "interpersonal"
significance.
Now suppose we drop the first inequality of either a or b (but not both). A game that meets the resulting conditions might be termed a common knowledge PD. As long as each player knows that the other is rational and each knows the other's ordering of payoffs, we still feel the force of the dilemma. For suppose b holds. Then D is the dominant move for Row. Column, knowing that Row is rational, knows that Row will defect, and so, by the remaining inequality in b, will defect himself. Similarly, if b holds Column will defect, and Row, realizing this, will defect herself. By c, the resulting (D,D) is again worse for both than (C,C).
| C | D | N | |
| C | R,R | S,T | T,S |
| D | T,S | P,P | R,S |
| N | S,T | S,R | S,S |
Here each player can choose "cooperate", "defect" or "neither" and the payoffs are ordered as before. Defection is no longer dominant, because each player is better off choosing C than D when the other chooses N. Nevertheless (D,D) is still the unique equilibrium. Let us label a game like this in which the selfish outcome is the unique equilibrium an equilibrium PD, and one in which the selfish outcome is a pair of dominant strategies a dominance PD. As will be seen below, attempts to "solve" the PD by allowing conditional strategies can create multiple- move games that are themselves equilibrium PDs.
A common view is that a multi-player PD structure is reflected in what Garitt Hardin popularized as "the tragedy of the commons." Each member of a group of neighboring farmers prefers to allow his cow to graze on the commons, rather than keeping it on his own inadequate land, but the commons will be rendered unsuitable for grazing if it is used by more than some threshold number use it. More generally, there is some social benefit B that each member can achieve if sufficiently many pay a cost C. We might represent the payoff matrix as follows:
| n or fewer choose C | more than n choose C | |
| C | C | C+B |
| D | 0 | B |
The cost C is assumed to be a negative number. The "temptation" here is to get the benefit without the cost, the reward is the benefit with the cost, the punishment is to get neither and the sucker payoff is to pay the cost without realizing the benefit. So the payoffs are ordered B > (B+C) >0 > C. As in the two- player game, it appears that D weakly dominates C for all players, and so rational players would choose D and achieve 0, while preferring that everyone would choose C and obtain C+B.
Unlike the more straightforward generalization, this matrix does reflect common social choices--between depleting and conserving a scarce resource, between using polluting and non-polluting means of manufacture or disposal, and between participating and not participating in a group effort towards some common goal. When n is small, it represents a version of what has been called the "volunteer dilemma". A group needs a few volunteers, but each member is better off if others volunteer. (Notice, however, that in a true volunteer dilemma, where only one volunteer is needed, n is zero and the top left outcome is impossible. Under these conditions D no longer dominates C and the game loses its PD flavor.) A particularly vexing manifestation of this game occurs when a vaccination known to have serious risks is needed to prevent the outbreak of a fatal disease. If enough of her neighbors get the vaccine, each person may be protected without assuming the risks.
The tragedy of the commons game diagramed above has a somewhat different character than the two-player PD. First, even if each player's moves are entirely independent of the others, the alternatives represented by the columns in the commons matrix above are no longer independent of the alternatives represented by the rows. My choosing C necessarily increases the chances that more than n people will choose C. To ensure independence we should really redraw the matrix as follows:
| fewer than n others choose C | n others choose C | more than n others choose C | |
| C | C | C+B | C+B |
| D | 0 | 0 | B |
But now we see that move D does not dominate C. When we are at the threshold of adequate cooperation, I am better off cooperating. Provided that n is large, however, it would seem that this effect could be ignored and we could assume, for practical purposes, that the payoff matrix is like the previous one.
Similarly, whereas we saw in the original PD that mutual defection was the only nash equilibrium, this game has two equilibria. One is universal defection, since any player unilaterally departing from that outcome will move from payoff 0 to C. But a second is the state of minimally effective cooperation, where the number of cooperators just exceeds the threshold n. A defector who unilaterally departs from that outcome will move from B to B+C and a cooperator who unilaterally departs will move from B+C to 0. This might suggest that the tragedy of the commons is less tragic than the PD, but in real life situations, it would seem unlikely that the participants would know when they are at the equilibrium point of minimally effective cooperation.
Furthermore, in the ordinary PD, universal cooperation is a pareto- optimal outcome, i.e., there is no outcome in which each player is at least as well off and some are better off. But in the commons game the only pareto optimal outcomes are those of minimally effective cooperation. Whether universal cooperation is nevertheless desirable may depend on the nature of the choices involved. In the medical example it may seem best to vaccinate everyone. In the agricultural example, however it seems foolish to stipulate that nobody use the commons. Someone who avoids vaccination in the former case is seen as a "free rider". An underused commons in the latter seems to exemplify "surplus cooperation."
Finally, it is worth noting that in a two-person version of the tragedy of the commons game (with threshold of one) we get a matrix that presents little or no dilemma.
| C | D | |
| C | B+C,B+C | C,0 |
| D | 0,C | 0,0 |
This game captures David Hume's example of a boat with one oarsman on the port side and another on the starboard. Mutual cooperation is identical to minimally effective cooperation and therefore is both an equilibrium outcome and a pareto optimal outcome.
The above representations of the tragedy of the commons make the
simplifying assumptions that the costs and benefits to each player are
the same, and that these costs and benefits are independent of the
number of players who cooperate. A somewhat more general account would
replace C and B by functions C(i,j) and B(i,j) representing the cost
of cooperation to player i when he is one of exactly j players who
cooperate and the benefit to player i when exactly j players
cooperate. For each player i, we suppose that there is some threshold
ti such that B(i,j) is not defined unless j>ti.
We may assume additional cooperation never reduces the benefit i gets
from general cooperation, i.e., B(i,j+1)B(i,j)
and that additional defection never reduces the cost i bears in
cooperating, i.e, C(i,j+1)C(i,j). Now suppose
that, for all players i, B(i,j)>(B(i,j+1)+C(i,j+1)) when j is greater
than the threshold for i but less than the total number of players,
and 0>C(i,j) when j is less than the threshold for i. Suppose
additionally that, for all i and all j greater than the threshold for
i, B(i,j)+C(i,j)>0. We then have a tragedy of the commons game, which
(if we ignore the outcome of minimally effective cooperation) presents
the familiar dilemma: defection is individually rational, but general
cooperation benefits everyone.
Phillip Pettit has pointed out that examples that might be represented as many-player PD's come in two flavors. The examples discussed above might be classified as free-rider problems. My temptation is to enjoy some benefits brought about by burdens shouldered by others. The other flavor is what Pettit calls "foul dealer" problems. My temptation is to benefit myself by hurting others. Suppose, for example, that a group of people are applying for a single job, for which they are equally qualified. If all fill out their applications honestly, they all have an equal chance of being hired. If one lies, however, he can ensure that he is hired while, let us say, incurring a small risk of being exposed later. If everyone lies, they again have an equal chance for the job, but now they all incur the risk of exposure. Thus a lone liar, by reducing the others' chances of employment from slim to none, raises his own chances from slim to sure. As Pettit points out, when the minimally effective level of cooperation is the same as the size of the population, there is no opportunity for free-riding (everyone's cooperation is needed), and so the PD must be of the foul-dealing variety. But (Pettit's contrary claim notwithstanding) not all foul-dealing PDs seem to have this feature. Suppose, for example, that two applicants in the story above will be hired. Then everyone gets the benefit (a chance of employment without risk of exposure) unless two or more players lie. Nevertheless, the liars seem to be foul dealers rather than free riders. A better characterization of the foul-dealing dilemma might be that every defection from a generally cooperative state strictly reduces the payoffs to the cooperators, i.e., for every player i and every j greater than i's threshold, either B(i,j+1)>B(i,j) or C(i,j+1)>C(i,j). A free-rider's defection benefits himself but does not, by itself, hurt the cooperators. A foul-dealer's defection benefits himself and hurts the cooperators.
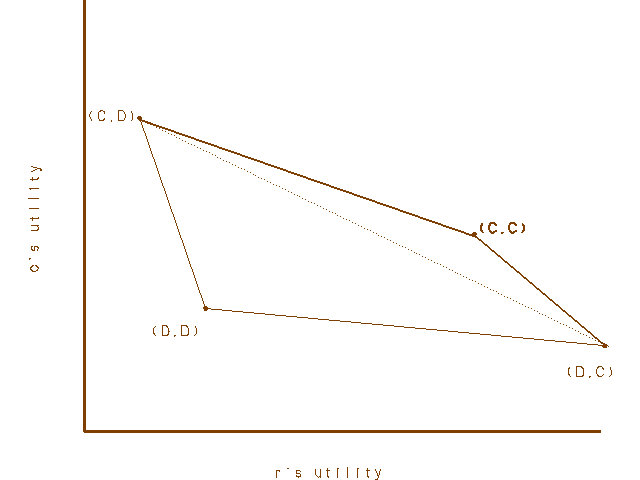
Figure 1a.
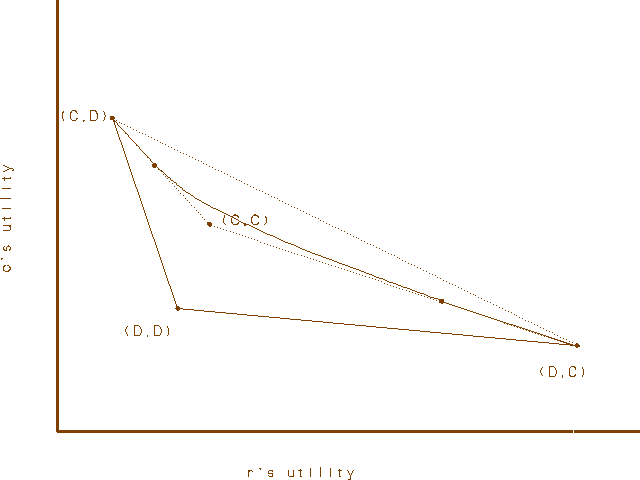
Figure 1b.
Here the x and y axes represent the utilities of Row and Column. The four outcomes entered in the matrix of the second section are represented by the labeled dots. Conditions PD3a and PD3b ensure that (C,D) and (D,C) lie northwest and southeast of (D,D), and PD3c is reflected in the fact that (C,C) lies northeast of (D,D). Suppose first that (D,D) and (C,C) lie on opposite sides of the line between (C,D) and (D,C), as in figure 1a. Then the four points form a convex quadrilateral, and the payoffs of the feasible outcomes of mixed strategies are represented by all the points on or within this quadrilateral. Of course a player can really only get one of four possible payoffs each time the game is played, but the points in the quadrilateral represent the expected values of the payoffs to the two players. If Row and Column cooperate with probabilities p and q (and defect with probabilities p*=1-p and q*=1-q), for example, then the expected value of the payoff to Row is p*qT+pqR+p*q*P+pq*S. A rational self- interested player, according to a standard view, should prefer a higher expected payoff to a lower one. In figure 1a the payoff for universal cooperation (with probability one) is pareto optimal among the payoffs for all mixed strategies. In figure 1b, however, where both (D,D) and (C,C) lie southwest of the line between (C,D) and (D,C), the story is more complicated. Here the payoffs of the feasible outcome lie within a figure bounded on the northeast by three distinct curve segments, two linear and one concave. Notice that (C,C) is now in the interior of the region bounded by solid lines, indicating that there are mixed strategies that provide both players a higher expected payoff than (C,C). It is important to note that we are talking about independent mixed strategies here. Row and Column use private randomizing devices and have no communication. If they were able to correlate their mixed strategies, so as to ensure, say (C,D) with probability p and (D,C) with probability p*, the set of feasible solutions would extend up to (and include) the dotted line between (C,D) and (D,C). The point here is that, even confined to independent strategies, there are some games satisfying PD3 in which both players can both do better than they do with universal cooperation. A PD in which universal cooperation is pareto optimal may be called a pure PD. A pure PD is characterized by adding to PD3 the following condition.
| P) | (Tr-Rr)(Tc-Rc)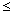 (Rr-Sr)(Rc-Sc) (Rr-Sr)(Rc-Sc)
|
|||||
In a symmetric game P reduces to the simpler condition
| RCA) | R1/2(T+S) |
|||||
(named after the authors Rappaport, Chammah and Axelrod who employed it).
A more radical revision assumes that the players have the property that David Gauthier has labeled transparency. A fully transparent player is one whose intentions are completely visible to others. Nobody holds that we humans are fully transparent, but the observation that we can often successfully predict what others will do suggests that we are at least "translucent." Furthermore agents of larger scale, like firms or countries, may be more transparent than we are. Thus there may be some theoretical interest in investigations of PDs with transparent players. Such players could presumably execute conditional strategies more sophisticated than those of the (non- transparent)extended game players, strategies, for example that are conditional on the conditional strategies employed by others. There is some difficulty, however, in determining exactly what strategies are feasible for such players. Suppose Row adopted the strategy "do the same as Column" and Column adopted the strategy "do the opposite of Row". There is no way that both these strategies could be satisfied. On the other hand, if each adopted the strategy "imitate the other player", there are two ways the strategies could be satisfied, and there is no way to determine which of the two they would adopt. Nigel Howard, who was probably the first to study such conditional strategies systematically, avoided this difficulty by insisting on a rigidly typed hierarchy of games. At the base level we have the ordinary PD game, where each player chooses between C and D. For any game G in the hierarchy we can generate two new games RG and CG. In RG, Column has the same moves as in game G and Row can choose any function that assigns C or D to each of Column's possible moves. Similarly in CG, Row has the same moves as in G and Column has a new set of conditional moves. For example, if [PD] is the base level game, then C[PD] is the game in which Column can choose from among the strategies Cu, Du, I and O mentioned above. Howard observed that in the two third level games RC[PD] and CR[PD] (and in every higher level game) there is an equilibrium outcome giving each player R. In particular, such an equilibrium is reached when one player plays I and the other cooperates when his opponent plays I and defects when his opponent plays Cu, Du or O. Notice that this last strategy is tantamount to Danielson's reciprocal cooperation.
The lesson of all this for rational action is not clear. Suppose two players in a PD were sufficiently transparent to employ the conditional strategies of higher level games. How do they decide what level game to play? Who chooses the imitation move and who chooses reciprocal cooperation? To make a move in a higher level game is presumably to form an intention observable by the other player. But why should either player expect the intention to be carried out if there is benefit in ignoring it?
Conditional strategies have a more convincing application when we take our inquiry as directed, not towards playing the PD, but as designing agents who would play it well with a variety of likely opponents. This is the viewpoint of [Danielson]. A conditional strategy is not an intention that a player forms as a move in a game, but a deterministic algorithm defining a kind of player. Indeed, one of the lessons of the PD may be that transparent agents are better off if they can form irrevocable "action protocols" rather than always following the intentions they may form at the time of action. Danielson does not limit himself a priori to strategies within Howard's hierarchy. An agent is simply a computer program, which can contain lines permitting other programs to read and execute it. We could easily write two such programs, each designed to determine whether its opponent plays C or D and to do the opposite. What happens when these two play a PD depends on the details of implementation, but it is likely that they will be "incoherent," i.e., they will enter endless loops and be unable to make any move at all. To be successful a program should be able to move when paired with a variety of other programs, including copies of itself, and it should be able to get valuable outcomes. Programs implementing I and O in a straightforward way are not likely to succeed because when paired with each other they will be incoherent. Programs implementing Du are not likely to succeed because they get only P when paired with their clones. Those implementing Cu are not likely to succeed because they get only S when paired with programs that recognize and exploit their unconditionally cooperative nature. There is some vagueness in the criteria of success. In Howard's scheme we could compare a conditional strategy with all the possible alternatives of that level. Here, where any two programs can be paired, that approach is senseless. Nevertheless, certain programs seem to do well when paired with a wide variety of players. One is a version of the strategy that Gauthier has advocated as constrained maximization. The idea is that a player j should cooperate if the other would cooperate if j did, and defect otherwise. As stated, this appears to be a strategy for the RC[PD] or CR[PD] games. It is not clear how a program implementing it would move (if indeed it does move) when paired with itself. Danielson is able to construct an approximation to constrained maximization, however, that does cooperate with itself. Danielson's program (and other implementations of constrained maximization) cannot be coherently paired with everything. Nevertheless it does move and score well against familiar strategies. It cooperates with Cu and itself and it defects against Du. If it is coherently paired it seems guaranteed a payoff no worse than P.
A second successful program models Danielson's reciprocal cooperation. Again, it is not clear that the strategy (as formulated above) allows it to cooperate (or make any move) with itself, but Danielson is able to construct an approximation that does. The (approximate) reciprocal cooperation does as well as (approximate) constrained maximization against itself, Du and constrained maximization. Against Cu it does even better, getting T where constrained maximization got only R.
Although there is good reason not to take the conclusion of the backwards induction argument too seriously, most of those who investigate the IPD still prefer to take the number of iterations to be undetermined. This is accomplished by including in the game specification a probability p (the "shadow of the future") such that at each round the game will continue with probability p. Alternatively, a "discount factor" p is applied to the payoffs after each round so that present payoffs are valued more highly than future. Mathematically, it makes little difference whether p is regarded as a probability of continuation or a discount on payoffs. The value of cooperation at a given stage in an IPD clearly depends on the odds of meeting one's opponent in later rounds. (This has been said to explain why the level of courtesy is higher in a village than a metropolis and why customers tend leave better tips in local restaurants than distant ones.) As p approaches zero, the IPD becomes the one-shot PD, and the value of defection increases. It is also customary to insist that the game has the property labeled RCA above, so that (in the symmetric game) players do better by cooperating on every round than they would do by "taking turns" -- you cooperate while I defect and then I cooperate while you defect.
The iterated version of the PD was discussed from the time the game was devised, but interest accelerated after influential publications of Robert Axelrod in the early eighties. Axelrod invited professional game theorists to submit computer programs for playing IPDs. All the programs were entered into a tournament in which each played every other (as well as a clone of itself and a strategy that cooperated and defected at random) hundreds of times. It is easy to see that in a game like this no strategy is "best" in the sense that its score would be highest among any group of competitors. If the other strategies never consider the previous history of interaction in choosing their next move, it would be best to defect unconditionally. If the other strategies all begin by cooperating and then "punish" any defection against themselves by defecting on all subsequent rounds, then a policy of unconditional cooperation is better. Nevertheless, as in the transparent game, some strategies have features that seem to allow them to do well in a variety of environments. The strategy that scored highest in Axelrod's initial tournament, Tit for Tat (henceforth TFT), simply cooperates on the first round and imitates its opponent's previous move thereafter. More significant than TFT's initial victory, perhaps is the fact that it won Axelrod's second tournament, whose sixty three entrants were all given the results of the first tournament. In analyzing the his second tournament, Axelrod noted that each of the entrants could be assigned one of five "representative" strategies in such a way that a strategy's success against a set of others can be accurately predicted by its success against their representative. As a further demonstration of the strength of TFT, he calculated the scores each strategy would have received in tournaments in which one of the representative strategies was five times as common as in the original tournament. TFT received the highest score in all but one of these hypothetical tournaments.
Axelrod attributed the success of TFT to four properties. It is nice, meaning that it is never the first to defect. The eight nice entries in Axelrod's tournament were the eight highest ranking strategies. It is retaliatory, making it difficult for it to be exploited by the rules that were not nice. It is forgiving, in the sense of being willing to cooperate even with those who have defected against it (provided their defection wasn't in the immediately preceding round). An unforgiving rule is incapable of ever getting the reward payoff after its opponent has defected once. And it is clear, presumably making it easier for other strategies to predict its behavior so as to facilitate mutually beneficial interaction.
Suggestive as Axelrod's discussion is, it is worth noting that the ideas are not formulated precisely enough to permit a rigorous demonstration of the supremacy of TFT. One doesn't know, for example, the extent of the class of strategies that might have the four properties outlined, or what success criteria might be implied by having them. It is true that if one's opponent is playing TFT (and the shadow of the future is sufficiently large) then one's maximum payoff is obtained by a strategy that results in mutual cooperation on every round. Since TFT is itself one such strategy this implies that TFT is a weak nash equilibrium in the space of all strategies. But that does not particularly distinguish TFT, for unconditional defection is also a weak nash equilibrium. Indeed, a "folk theorem" of iterated game theory (now widely published--see, for example, Binmore pp 373-377) implies that, for any p, 0<=p<=1 there is a nash equilibrium in which p is the fraction of times that mutual cooperation occurs.
The predominant view seems to be that, when imperfection is inevitable, successful strategies will have to be more forgiving of defections by their opponents (since those defections might well be unintended). Molander demonstrates that strategies that mix TFT with Cu do approach a payoff of R as the probability of error approaches zero. When these mixes play each other, they benefit from higher ratios of Cu to TFT, but if they become too generous, they risk exploitation by "stingy" strategies that mix TFT> with defection. Nowak and Sigmund calculate that when the mix is set so that, following a defection, one cooperates with probability g(R,P,T,S)=min{(1-(T-R)/(R-S)), (R-P)/(T-P)}, the generous strategies will get the highest score with each other that is possible other without allowing stingy strategies to do better against them than TFT does. This mix is known as generous TFT.
The idea that the presence of imperfection induces greater forgiveness or generosity is only plausible for low levels of imperfection. As the level of imperfection approaches 1/2, Imperfect TFT becomes indistinguishable from the random strategy, for which the very ungenerous Du is the best reply. A simulation by Kollock seems to confirm that at high levels of imperfection, more stinginess is better policy than more forgiveness. But Bendor, Kramer and Swistak note that the strategies employed in the Kollock simulation are not representative and so the results must be interpreted with caution.
A second idea is that an imperfect environment encourages strategies to observe their opponent's play more carefully. In a tournament similar to Axelrod's (Donninger) in which each player's moves were subject to a 10% chance of alteration, TFT finished sixth out twenty-one strategies. As might have predicted on the dominant view, it was beaten by the more generous Tit-for-Two-Tats (which cooperates unless defected against twice in a row). It was also beaten, however, by two versions of Downing, a program that bases each new move on its best estimate how responsive its opponent has been to its previous moves. In Axelrod's two original tournaments, Downing had ranked near the bottom third of the programs submitted. Bendor (1987) demonstrates deductively that against imperfect strategies there are advantages to basing one's probability of defection on longer histories than does TFT.
One clever implementation of the idea that a strategies in an
imperfect environment should pay attention to their previous
interactions is the family of "Pavlovian" strategies investigated by
Kraines and Kraines. For each natural number n n-Pavlov, or
Pn, adjusts its probability of cooperation in units of 1/n,
according to how well it fared on the previous round. More precisely,
if Pn was cooperating with probability p on the last round,
then on this round it will cooperate with probability p[+](1/n) if it
received the reward payoff on the previous round, p[-](1/n) if it
received the punishment payoff, p[+](2/n)if it received the temptation
payoff, and p[-](2/n) if it received the sucker payoff. [+] and [-]
are bounded addition and subtraction, i.e., x[+]y is the sum x+y
unless that number exceeds one, in which case it is one (or as close
to one as the possibility of error allows), and x[-]y is similarly
either x-y or close to zero. Strictly speaking, Pn is not
fully specified until an initial probability of cooperation is given,
but for most purposes the value of that parameter becomes
insignificant in sufficiently long games and can be safely ignored.
It may appear that Pn requires far more computational resources
to implement than, say, TFT. Each move for the latter depends
on only on its opponent's last move, whereas each move for Pn
is a function of the entire history of previous moves of both players.
Pn, however, can always calculate its next move by tracking
only its current probability of cooperation and its last payoff. As
its authors maintain, this seems like "a natural strategy in the
animal world." One can calculate that for n>1, Pn does better
against the random strategy than does TFT. More generally,
Pn does as well or better than TFT against the generous
unresponsive strategies Cp that always cooperate with fixed
probability p1/2 (because an occasional temptation payoff can teach
it to exploit the unresponsive strategies.) In these cases the "slow
learner" versions of Pavlov with higher values of n do slightly better
than the "fast learners" with low values. Against responsive
strategies, like other Pavlovian strategies and TFT, Pn
and its opponent eventually reach a state of (almost) constant
cooperation. The total payoff is then inversely related to the
"training time," i.e., the number of rounds required to reach that
state. Since training time of Pn varies exponentially with n,
Kraines and Kraines maintain that P3 or P4 are to be
preferred to other Pavlovian strategies, and are close to "ideal" IPD
strategies. It should be noted, however, that when (deterministic)
TFT plays itself, no training time at all is required, whereas
when a Pavlovian strategy plays TFT or another Pavlov, the
training time can be large. Thus the cogency of the argument for the
superiority of Pavlov over TFT depends on the observation that
its performance shows less degradation when subject to imperfections.
It is also worth remembering that no strategy is best in every
environment, and the criteria used in defense of various strategies in
the IPD are vague and heterogeneous. One advantage of the evolutionary
versions of the IPD discussed in the next section is that they permit
more careful formulation and evaluation of success criteria.
The initial population in an EPD can be represented by a set of pairs {(p1,s1),...(pn,sn)} where p1,...,pn are the proportions of the population playing strategies s1,...,sn, respectively. The description of EPD's given above does not specify exactly how the population of strategies is to be reconstituted after each IPD. The usual assumption, and the most sensible one for biological applications, is that a score in any round indicates the relative number of "offspring" in the next. It is assumed that the size of the entire population stays fixed, so that births of more successful strategies are exactly offset by deaths of less successful ones. This amounts to the condition that the proportion pi* of each strategy si in the successor population is determined by the equation pi*=pi(Vi/V), where Vi is the score of si in the previous round and V is the average of all scores in the population. Thus every strategy that scores above the population average will increase in number and every one that scores below the average will decrease. This kind of evolution is referred to as "replication dynamics" or evolution according to the "proportional fitness" rule. Other rules of evolution are possible. Bendor and Swistak argue that, for social applications, it makes more sense to think of the players as switching from one strategy to another rather than as coming into and of existence. Since rational players would presumably switch only to strategies that received the highest payoff in previous rounds, only the highest scoring strategies would increase in numbers. Discussion here, however will primarily concern EPDs with the proportional fitness rule.
Axelrod, borrowing from Trivers and Maynard Smith, includes a description of the EPD with proportional fitness, and a brief analysis of the evolutionary version of the tournament described in the section on iteration. For Axelrod, the EPD provides one more piece of evidence in favor of TFT:
"TIT FOR TAT had a very slight lead in the original tournament, and never lost this lead in simulated generations. By the one-thousandth generation it was the most successful rule and still growing at a faster rate than any other rule."
Axelrod's EPD tournament, however, incorporated several features that might be deemed artificial. First, it permitted deterministic strategies in a noise-free environment. As noted above, TFT can be expected to do worse under conditions that model the inevitability of error. Second, it began with only the 63 strategies from the original IPD tournament. Success against strategies concocted in the ivory tower may not imply success against all those that might be found in nature. Third, the only strategies permitted to compete at a given stage were the survivors from the previous stage. A more realistic model, one might argue, would allow new "mutant" strategies to enter the game at any stage. Changing this third feature might well be expected to hurt TFT. For a large growth in the TFT population would make it possible for mutants employing more naive strategies like Cu to regain a foothold, and the presence of these naifs in the population might favor nastier strategies like Du over TFT.
Sigmund and Nowak simulated two kinds of tournaments that avoid the three questionable features. The first examined the family of "reactive" strategies. For any probabilities y, p, and q, R(y,p,q) is the strategy of cooperating with probability y in the first round and thereafter with probability p if the other player has cooperated in the previous round, and with probability q if she has defected. This is a broad family, including many of the strategies already considered. Cu, Du, TFT, and Cp are R(1,1,1), R(0,0,0), R(1,1,0), and R(p,p,p). To capture the inevitability of error, Sigmund and Nowak exclude the deterministic strategies, where p and q are exactly 1 or 0, from their tournaments. As before, if the game is sufficiently long, the first move can be ignored and a reactive strategy can be identified with its p and q values. Particular attention is paid to the case where p is close to 1 and q=min{(1-(T-R)/(R-S)), (R-P)/(T-P). It can be shown that a homogeneous population adopting this strategy, known as TFT, will get a higher payoff than one adopting any other unexploitable reactive strategies (where unexploitability suitably defined). The first series of Nowak and Sigmund's EPD tournaments begin with representative samples of reactive strategies. For most such tournaments, they found that evolution led irreversibly to Du. Those strategies R(p,q) closest to R(0,0) thrived while the others perished. When one of the initial strategies is very close to TFT, however, the outcome changes.
"TFT and all other reciprocating strategies (near (1,0)) seem to have disappeared. But an embattled minority remains and fights back. The tide turns when `suckers' are so decimated that exploiters can no longer feed on them. Slowly at first, but gathering momentum, the reciprocators come back, and the exploiters now wane. But the TFT-like strategy that caused this reversal of fortune is not going to profit from it: having eliminated the exploiters, it is robbed of its mission and superseded by the strategy closest to GTFT [= generous TFT]. Evolution then stops. Even if we introduce occasionally 1% of another strategy it will vanish."On the basis of their tournaments among reactive strategies, Nowak and Sigmund conjectured that, while TFT is essential for the emergence of cooperation, the strategy that actually underlies persistent patterns of cooperation in the biological world is more likely to be generousTFT. A second series of simulations with a wider class of strategies, however, forced them to revise their opinion. The strategies considered in the second series allowed each player to base its probability of cooperation on its own previous move as well as its opponent's. A strategy can now be represented as S(p1,p2,p3,p4) where p1, p2, p3, p4 are the probabilities of defecting after outcomes (C,C), (C,D), (D,C), and (D,D), respectively i.e., after receiving the reward, sucker, temptation and punishment payoffs. The initial population in these tournaments all play the random strategy S(.5,.5,.5,.5) and after every 100 generations a small amount of a randomly chosen (non-deterministic) mutant is introduced, and the population evolves by proportional fitness. The results are quite different than before. After 107 generations, a state of steady mutual cooperation was reached in 90% of the simulation trials. But less than 8.3% of these states were populated by players using TFT or generous TFT. The remaining 91.7% were dominated by strategies close to S(1,0,0,1). This is the just the Pavlovian strategy P1 of Kraines and Kraines, which cooperates after receiving R or T and defects after receiving P or S. Kraines and Kraines had been somewhat dismissive of P1. They recall that Rappaport and Chammah, who identified it early in the history of game theory had labeled it "simpleton" and remark that "the appellation is well deserved". Indeed, P1 has the unfortunate characteristic of trying to cooperate with Du on every other turn, and against TFT it can get locked into the inferior repeating series of payoffs T,P,S,T,P,S,... . But Sigmund and Nowak's simulations suggest that these defects do not matter very much in evolutionary contexts. One reason may be that P1 helps to make its environment unsuitable for its enemies. Du does well in an environment with generous strategies, like Cu or generous TFT. TFT, as we have seen, allows these strategies to flourish, which could pave the way for Du Thus, although TFT fares less badly against Du than P1 does, P1 is better at keeping its environment free of Du.
One might expect it to be possible to predict the strategies that will prevail in EPDs meeting various conditions, and to justify such predictions by formal proofs. Until very recently, however, mathematical analyses of the EPD have been plagued by conceptual confusions. The important solution concept for this kind of game is "evolutionary stability," the condition under which, as Nowak and Sigmund say, "evolution stops". Axelrod and Axelrod and Hamilton, using concepts borrowed from Maynard Smith and Trivers, claim to show that TFT was evolutionary stable. Boyd and Lorberbaum and Farrell and Ware include proofs demonstrating that no strategies are evolutionarily stable. Unsurprisingly, the paradox is resolved by observing that the two groups of authors employ slightly different conceptions of evolutionary stability. The conceptual tangle is unraveled in a series of papers by Bendor and Swistak. The correct story is summarized below. For those interested, the link in this sentence provides a brief guide to concepts of stability that appear in the literature.
A strategy s is strongly stable for an EPD if a population playing strategy s will drive to extinction any sufficiently small group of invaders. If an EPD evolves according to the proportional fitness rule, strong stability requires that either the invaders do strictly worse against the natives than the natives themselves do against the natives or else that the invaders get exactly the same payoff against the natives as the natives themselves do, but the native does better against the invader than the invader himself does. Using the notation V(i,j) for the payoff to i when i plays j, this is a condition identified by Maynard Smith
| MS) | For all strategies j, V(i,i) > V(j,i) or both V(i,i)=V(j,i) and V(i,j)>V(j,j) | |||||
For any strategy i in the PD (or indeed in any finite game), however, there are strategies j different from i such that j mimics the way i plays when it plays against i or j. The existence of these "neutral mutants" implies that MS cannot be satisfied and so no EPD (and indeed no finite evolutionary game of any sort) is strongly stable.
A strategy s is weakly stable for an EPD if, in a population playing s, any group of invaders of sufficiently small size will fail to drive the native population to extinction. If the EPD evolves according to the proportional fitness rule, this is equivalent to a weak version of MS identified by Bendor and Swistak.
| BS) | For all strategies j, V(i,i) > V(j,i) or both V(i,i)=V(j,i) and V(i,j)V(j,j) |
|||||
Weakly stable strategies for EPDs that evolve according to the proportional fitness rule do exist. This does not particularly vindicate any of the strategies discussed above, however. Bendor and Swistak prove a result analogous to the folk theorem mentioned above: If the shadow of the future is sufficiently large, there are weakly stable strategies supporting any degree of cooperation from zero to one. One way to distinguish among the weakly stable strategies is by the size of the invasion required to overturn the natives, or, equivalently, by the proportion of natives required to maintain stability. Bendor and Swistak show that this number, the minimal stabilizing frequency, never exceeds 1/2: no population can resist every invading group as large as itself. This result, Bendor and Swistak maintain, does allow them to begin to provide a theoretical justification for Axelrod's claims. They are able to show that, as the shadow of the future approaches one, any strategy that is nice (meaning that it is never first to defect) and retaliatory (meaning that it always defects immediately after it has been defected against) is weakly stable with minimal stabilizing frequency approaching one half. TFT has both these properties and, in fact, they are the first two of the four properties Axelrod cited as instrumental to TFT's success. There are, of course, many other nice and retaliatory strategies, and there are strategies (like P1) that are not retaliatory but still weakly stable. But Bendor and Swistak are at least able to show that any "maximally robust" weakly stable strategy, i.e., any strategy whose minimum stabilizing frequency approaches one half, chooses cooperation on all but a finite number of moves in an infinitely repeated PD.
Bendor and Swistak's results must be interpreted with some care. First, one should keep in mind that no probabilistic or noise- sensitive strategies can fit the definitions of either "nice" or "retaliatory" strategies. Furthermore, imperfect versions of TFT are not weakly stable. They can be overthrown by arbitrarily small invasions of deterministic TFT or, indeed, by arbitrary small invasions of any less imperfect TFT. Second, one must remember that the results about minimal stabilizing frequencies only concern weak stability. If the number of generations is large compared with the original population (as it often is in biological applications), a population that is initially composed entirely of players employing the same maximally robust strategy, could well admit a sequence of small invading groups that eventually reduces the original strategy to less than half of the population. At that point the original strategy could be overthrown.
It is likely that both of these caveats play some role in explaining an apparent discrepancy between the Bendor/Swistak results and the Nowak/Sigmund simulations. One would expect Bendor/Swistak's minimal stabilizing frequency to provide some indication of the length of time that a population plays a particular strategy. A strategy requiring a large invasion to overturn is likely to prevail longer than a strategy requiring only a small invasion. A straightforward calculation reveals that P1 has a relatively low minimum stabilizing frequency. It is overturned by invasions of unconditional defectors exceeding 10% of the population. Yet in the Nowak/Sigmund simulations, P1- like strategies predominate over TFT-like strategies. Since the simulations required imperfection and since they generated a sequence of mutants vastly larger than the original population, there is no real contradiction here. Nevertheless the discrepancy suggests that we do not yet have a theoretical understanding of EPD's sufficient to predict the strategies that will emerge under various plausible conditions.
As usual, the impetus here seems to come from Axelrod. Axelrod randomly distributed four copies of each of the 63 strategies submitted to his tournament on a grid arranged so that each cell had four neighbors. For every initial random distribution, the resulting SPD eventually reached a state where the strategy in every cell was cooperating with all its neighbors, at which point no further evolution is possible. Only about ten of the 63 original strategies remained in these end-states, and they were no longer randomly distributed, but segregated into clumps of various sizes. Axelrod also showed that under special conditions evolution in an SPD can create successions of complex symmetrical patterns that do not appear to reach any steady-state equilibrium.
Nowak and May have investigated in greater detail SPD's in which the only permitted strategies are Cu and Du. (These are the strategies appropriate among individuals lacking memory or recognition skills.) They find that, for a variety of spatial configurations, and distributions of strategies evolution depends on relative payoffs in a uniform way. When the temptation payoff is sufficiently high clusters of Du grow and those of Cu shrink and when it is sufficiently low the Du clusters shrink and the Cu ones grow. For a narrow range of intermediate values, we get more of the complicated patterns noted above. The evolving patterns exhibit great variety, but for a given spatial configuration the ratio of the two strategies seems to approach the same constant value for all initial distributions of strategies and all payoffs within the special range. More recently, Nowak, Boenhoeffer and May have observed similar phenomena under a variety of error-conditions identified by Mukherji and Rajan, although cooperators seem to require lower relative temptation values to thrive under these conditions, and the level of error must be sufficiently low.
Spatial PD's seem thus far to have made rather little contribution to biological or social theory, but they have certainly given us lots of pretty pictures. The interested surfer can see an example constructed by Hatae Tsutomo via the link at the end of the entry.
First published: September 4, 1997
Content last modified: September 20, 1997
 Table of Contents
Table of Contents