

Formal Representations of Belief
Epistemology is the study of knowledge and justified belief. Belief is thus central to epistemology. It comes in a qualitative form, as when Sophia believes that Vienna is the capital of Austria, and a quantitative form, as when Sophia's degree of belief that Vienna is the capital of Austria is at least twice her degree of belief that tomorrow it will be sunny in Vienna. Formal epistemology, as opposed to mainstream epistemology (Hendricks 2006), is epistemology done in a formal way, that is, by employing tools from logic and mathematics. The goal of this entry is to give the reader an overview of the formal tools available to epistemologists for the representation of belief. A particular focus will be the relation between formal representations of qualitative belief and formal representations of quantitative degrees of belief.
- 1. Preliminaries
- 2. Subjective Probability Theory
- 3. Other Accounts
- Bibliography
- Other Internet Resources
- Related Entries
1. Preliminaries
1.1 Formal Epistemology versus Mainstream Epistemology
One can ask many questions about belief and the relation between belief and degrees of belief. Many of them can be asked and answered informally as well as formally. None of them can be asked or answered only informally in the sense that it would be logically impossible to ask or answer them formally - although it is, of course, often impossible for us to do so. Just think of how you would come up with a counterexample to the claim that some questions can be asked or answered only informally. You would list objects, and properties of these, and maybe even relations between them. But then you already have your formal model of the situation you are talking about. On the other hand, some epistemological questions can only be answered formally, as is illustrated by the following example (modeled after one given by Sven Ove Hansson in Hendricks & Simons 2005).
Consider the following two proposals for a link between the qualitative notion of belief and the quantitative notion of degree of belief. According to the first proposal an agent should believe a proposition if and only if her degree of belief that the proposition is true is higher than her degree of belief that the proposition is false (Weatherson 2005). According to the second proposal (known as the Lockean thesis and discussed in section 2.6) an agent should believe a proposition if and only if her degree of belief for that proposition is higher than a certain threshold. We can ask formally as well as, maybe, informally under which conditions these two proposals are equivalent, but we can answer this question only formally.
That provides one reason why we should care about formal representations of belief, and formal epistemology in general.
1.2 The Objects of Belief
Before we can investigate the relation between various beliefs and degrees of belief, we have to get clear about the relata of the (degree of) belief relation. It is common to assume that belief is a relation between an epistemic agent at a particular time to an object of belief. Degree of belief is then a relation between a number, an epistemic agent at a particular time, and an object of belief. It is more difficult to state just what these objects of belief are. Are they sentences or propositions expressed by sentences or possible worlds (whatever these are: see Stalnaker 2003) or something altogether different?
The received view is that the objects of belief are propositions, i.e., sets of possible worlds or truth conditions. A more refined view is that the possible worlds comprised by those propositions are centered at an individual at a given time (Lewis 1979). Whereas a(n) (uncentered) possible world completely specifies a way the world might be, a centered possible world additionally specifies who one is when in a given (uncentered) possible world. In the latter case propositions are often called properties. Most epistemologists stay very general and assume only that there is a non-empty set W of possibilities such that exactly one element of W corresponds to the actual world. If the possibilities in W are centered, the assumption is that there is exactly one element of W that corresponds to your current time slice in the actual world (Lewis 1986 holds that this element not merely corresponds to, but is identical with, your current time slice in the actual world).
Centered propositions are needed to adequately represent self-locating beliefs such as Sophia's belief that she lives in Vienna, which may well be different from her belief that Sophia lives in Vienna (these two beliefs differ if Sophia does not believe that she is Sophia). Self-locating beliefs have important epistemological consequences (Elga 2000, Lewis 2001, Titelbaum to appear) and centered propositions are ably argued by Egan (2006) to correspond to what philosophers have traditionally called secondary qualities (Locke 1690/1975). Lewis' (1979, 133ff) claim that the difference between centered and uncentered propositions plays little role in how belief and other attitudes are formally represented and postulated to behave in a rational way can only be upheld for synchronic constraints on the statics of belief. For diachronic constraints on the dynamics of belief this claim is false, because the actual centered world (your current time slice in the actual uncentered world) is continually changing as time goes by. We will bracket these complications, though, and assume that, unless noted otherwise, the difference between centered and uncentered possibilities and propositions has no effect on the topic at issue.
1.3 The Structure of the Objects of Belief
Propositions have a certain set-theoretic structure. The set of all possibilities, W, is a proposition. Furthermore, if A and B are propositions, then so are the complement of A with respect to W, W \ A, as well as the intersection of A and B, A∩B. In other words, the set of propositions is a (finitary) field or algebra A over a non-empty set W of possibilities: a set that contains W and is closed under complementation and finite intersection. Sometimes the field A of propositions is assumed to be closed not only under finite, but also under countable intersection. This means that A1∩…An∩… is a proposition (an element of A), if each of A1,…,An,… is. Such a field A is called a σ-field. Finally, a field A is complete just in case the intersection ∩B = ∩A∈BA is in A, for each subset B of A.
If Sophia believes today (to degree .55) that tomorrow it will be sunny in Vienna, but she does not believe today (to degree .55) that tomorrow it will not be not sunny in Vienna, propositions cannot be the objects of Sophia’s (degrees of) belief(s) today. That tomorrow it will be sunny in Vienna and that tomorrow it will not be not sunny in Vienna is one and the same proposition (if stated by the same person at the same time). It is merely expressed by two different, but logically equivalent sentences. (Some philosophers think that propositions are too coarse-grained as objects of belief, while sentences are too fine-grained. They take the objects of belief to be structured propositions, which are usually taken to be more fine-grained than ordinary propositions but less fine-grained than sentences. For an overview see the entry on structured propositions. Other philosophers think that ordinary propositions are just fine, but that they should be viewed as sets of epistemic rather than metaphysical or logical possibilities, although some philosophers think these do not differ.)
Sometimes sentences of a formal language L are taken to be the objects of belief. In that case the above mentioned set-theoretic structure translates into the following requirements: the tautological sentence ⊤ is a sentence of the language L; and whenever α and β are sentences of L, then so are the negation of α, ¬α, as well as the conjunction of α and β, α∧β. However, as long as logically equivalent sentences are required to be assigned the same degree of belief — and all accounts considered here require this — the difference between taking the objects of beliefs to be sentences of a formal language L and taking them to be propositions from a finitary field A is mainly cosmetic. The reason is that each language L induces a finitary field A over the set of all models or classical truth value assignments for L, ModL: A is the set of propositions over ModL that are expressed by the sentences in L. A in turn induces a unique σ-field, viz. the smallest σ-field σ(A) that contains A (σ(A) is the intersection of all σ-fields that contain A as a subset). A also induces a unique complete field, viz. the smallest complete field, call it γ(A), that contains A (γ(A) is the intersection of all complete fields that contain A as a subset). In the present case where A is generated by ModL, γ(A) is the powerset of ModL, ℘(ModL).
σ(A), and hence γ(A), will often contain propositions that are not expressed by a sentence of L. For instance, let αi be the sentence “You should donate at least i dollars to the Society for Exact Philosophy (SEP)”, for each natural number i. Assume our language L contains each αi and whatever else it needs to contain to be a language (e.g. the negation of each αi, ¬αi, as well as the conjunction of any two αi and αj, αi∧αj). L generates the following finitary field A of propositions: A = {Mod(α) ⊆ ModL: α ∈ L}, where Mod(α) is the set of models in which α is true. A in turn induces σ(A). σ(A) contains the proposition that there is no upper bound on the number of dollars you should donate to the SEP, Mod(α1)∩…∩Mod(αn)∩…, while there is no sentence in L that expresses this proposition.
Hence, if we start with a language L, we automatically get a field A induced by L. As we do not always get a language L from a field A, the semantic framework of propositions is more general than the syntactic framework of sentences.
2. Subjective Probability Theory
Subjective probability theory is by far the best developed account of degrees of belief. As a consequence, there is much more material to be presented here than in the case of other accounts. This section is structured into six subsections. The topics of these subsections will also be discussed in the sections on Dempster-Shafer theory, possibility theory, ranking theory, belief revision theory, and nonmonotonic reasoning. However, as there is much less (philosophical) literature on the latter accounts, there will not be separate subsections there.
2.1 The Formal Structure
Sophia believes to degree .55 that tomorrow it will be sunny in Vienna. Normally degrees of belief are taken to be real numbers from the interval [0,1], but we will consider an alternative below. If the ideally rational epistemic agent is certain that a proposition is true, her degree of belief for that proposition is 1. If the ideally rational epistemic agent is certain that a proposition is false, her degree of belief for that proposition is 0. However, these are extreme cases. Usually we are neither certain that a proposition is true nor that it is false. That does not mean, though, that we are agnostic with respect to the question whether the proposition we are concerned with is true. Our belief that it is true may well be much stronger than that it is false. Degrees of belief quantify the strength of such belief.
The dominant theory of degrees of belief is the theory of subjective probabilities. On this view, degrees of belief simply follow the laws of probability. Here is the standard definition due to Kolmogorov (1956). Let A be a field of propositions over a set W of possibilities. A function Pr: A → ℜ from A into the set of real numbers, ℜ, is a (finitely additive and unconditional) probability measure on A if and only if for all propositions A, B in A:
- Pr(A) ≥ 0
- Pr(W) = 1
- Pr(A∪B) = Pr(A) + Pr(B) if A∩B = ∅
The triple <W, A, Pr> is a (finitely additive) probability space. Suppose A is also closed under countable intersections (and thus a σ-field), and suppose Pr additionally satisfies, for all propositions Ai in A,
- Pr(A1∪…∪An∪…) = Pr(A1) + … + Pr(An) + … if Ai∩Aj = ∅ whenever i ≠ j.
Then Pr is a σ- or countably additive probability measure on A (Kolmogorov 1956, ch. 2, actually gives a different but equivalent definition; see e.g. Huber 2007a, sct. 4.1). In this case <W, A, Pr> is a σ- or countably additive probability space.
A probability measure Pr on A is regular just in case Pr(A) > 0 for every non-empty or consistent proposition A in A. Let APr be the set of all propositions A in A with Pr(A) > 0. The conditional probability measure Pr(·|-): A×APr → ℜ on A (based on the unconditional probability measure Pr on A) is defined for all pairs propositions A in A and B in APr by the ratio
- Pr(A|B) = Pr(A∩B)/Pr(B)
(Kolmogorov 1956, ch. 1, §4). The domain of the second argument place of Pr(·|-) is restricted to APr, since the ratio Pr(A∩B)/Pr(B) is not defined if Pr(B) = 0. Note that Pr(·|B) is a probability measure on A, for every proposition B in APr. Some authors take conditional probability measures Pr(·, given ·): A×A → ℜ as primitive and define (unconditional) probability measures in terms of them as Pr(A) = Pr(A, given W) for all propositions A in A. See Hájek (2003).
2.2 Interpretations
What does it mean to say that Sophia's subjective probability for the proposition that tomorrow it will be sunny in Vienna equals .55? This is a difficult question. Let us first answer a different one. How do we measure Sophia's subjective probabilities? On one account Sophia's subjective probability for A is measured by her betting ratio for A, i.e., the highest price she is willing to pay for a bet that returns $1 if A, and $0 otherwise. On a slightly different account Sophia's subjective probability for A is measured by her fair betting ratio for A, i.e., that number r = b/(a + b) such that she considers the following bet to be fair: $a if A, and $-b otherwise (a, b ≥ 0 with inequality for at least one). As we may say it: Sophia considers it to be fair to bet you b to a that A.
It is not irrational for Sophia to be willing to bet you $5.5 to $4.5 that tomorrow it will be sunny in Vienna, but not be willing to bet you $550,000 to $450,000 that this proposition is true. This uncovers one assumption of the measurement in terms of (fair) betting ratios: the epistemic agent is assumed to be neither risk averse nor risk prone. Gamblers in the casino are risk prone: they pay more for playing roulette than the fair monetary value according to reasonable probabilities (this may be perfectly reasonable if the additional cost is what the gambler is willing to spend on the thrill she gets out of playing roulette). Sophia, on the other hand, is risk averse — and reasonably so! — when she refuses to bet you $100,000 to $900,000 that it will be sunny in Vienna tomorrow, while she is happy to bet you $5 to $5 that this proposition is true. As an at best moderately wealthy philosopher, she might lose her standard of living along with this bet. Note that it does not help to say that Sophia's fair betting ratio for A is that number r = b/(a + b) such that she considers the following bet to be fair: $1 − r = a/(a + b) if A, and $-r = -b/(a + b) otherwise (a, b ≥ 0 with inequality for at least one). Just as stakes of $1,000,000 may be too high for the measurement to work, stakes of $1 may be too low.
Another assumption is that the agent's (fair) betting ratio for a proposition is independent of the truth value of this proposition. Obviously we cannot measure Sophia's subjective probability for the proposition that she will be happily married by the end of the week by offering her a bet that returns $1 if she will, and $0 otherwise. Sophia's subjective probability for getting happily married by the end of the week will be fairly low (as a hardworking philosopher she does not have much time to date). However, assuming that getting happily married is something she highly desires, her betting ratio for this proposition will be fairly high.
Ramsey (1926) avoids the first assumption by using utilities instead of money. He avoids the second assumption by presupposing the existence of an “ethically neutral” proposition (a proposition whose truth or falsity does not affect the agent's utilities) which the agent takes to be just as likely to be true as she takes it to be false. See Section 3.5 of the entry on interpretations of probability.
Let us return to our question of what it means for Sophia to assign a certain subjective probability to a given proposition. It is one thing for Sophia to be willing to bet at particular odds or to consider particular odds as fair. It is another thing for Sophia to have a subjective probability of .55 that tomorrow it will be sunny in Vienna. Sophia's subjective probabilities are measured by, but not identical to her (fair) betting ratios. The latter are operationally defined and observable. The former are unobservable, theoretical entities that, following Eriksson & Hájek (2007), we should take as primitive.
2.3 Justifications
The theory of subjective probabilities is not an adequate description of people's epistemic states (Kahneman, Slovic & Tversky 1982). It is a normative theory that tells us how an ideally rational epistemic agent's degrees of belief should behave. The thesis that an ideally rational agent's degrees of belief should obey the probability calculus is known as probabilism. So, why should such an agent's degrees of belief obey the probability calculus?
The Dutch Book Argument provides an answer to this question. (Cox's theorem, Cox 1946, and the representation theorem of measurement theory, Krantz, Luce, Suppes & Tversky 1971, provide two further answers.) On its standard pragmatic reading, the Dutch Book Argument starts with a link between degrees of belief and betting ratios. The second premise says that it is (pragmatically) defective to accept a series of bets which guarantees a sure loss. Such a series of bets is called a Dutch Book (hence the name ‘Dutch Book Argument’). The third ingredient is the Dutch Book Theorem. The standard pragmatic version says that an agent's betting ratios obey the probability calculus if and only if an agent who has those betting ratios cannot be Dutch Booked (i.e., presented a series of bets each of which is acceptable according to those betting ratios, but their combination guarantees a loss). From this it is inferred that it is (epistemically) defective to have degrees of belief that do not obey the probability calculus. Obviously this argument would be valid only if the link between degrees of belief and betting ratios were identity (in which case there would be no difference between pragmatic and epistemic defectiveness) - and we have already seen that it is not.
Hence there is a depragmatized Dutch Book Argument (cf. Armendt 1993, Christensen 1996, Ramsey 1926, Skyrms 1984). From a link between degrees of belief and fair betting ratios and the assumption that it is (epistemically) defective to consider a Dutch Book as fair, it is inferred that it is (epistemically) defective to have degrees of belief that violate the probability calculus. The version of the Dutch Book Theorem that licenses this inference says that an agent's fair betting ratios obey the probability calculus if and only if the agent never considers a Dutch Book as fair. The depragmatized Dutch Book Argument is a more promising justification for probabilism. See, however, Hájek (2005) and Hájek (2008).
Joyce (1998) attempts to vindicate probabilism by considering instead the accuracy of degrees of belief. The basic idea here is that a degree of belief function is (epistemically) defective if there exists an alternative degree of belief function that is more accurate in each possible world. The accuracy of a degree of belief b(A) in a proposition A in a world w is identified with the distance between b(A) and the truth value of A in w, where 1 represents true and 0 represents false. For instance, a degree of belief up to 1 in a true proposition is more accurate, the higher it is - and perfectly accurate if it equals 1. The overall accuracy of a degree of belief function b in a world w is then determined by the accuracy of the individual degrees of belief b(A). Given some conditions on how to measure distance or inaccuracy, Joyce is able to prove that a degree of belief function obeys the probability calculus if and only if there exists no alternative degree of belief function that is more accurate in each possible world (the only-if-part is not explicitly mentioned in Joyce 1998, but needed for the argument to work and present in Joyce 2009). Therefore, degrees of belief should obey the probability calculus.
The objection, known as Bronfman's objection, that has attracted most attention starts by noting that Joyce's conditions on measures of inaccuracy do not determine a single measure, but rather a whole set of such measures. This would strengthen rather than weaken Joyce's argument, were it not for the fact that these measures differ in their recommendations as to which alternative degree of belief function a non-probabilistic degree of belief function should be replaced by. All of Joyce's measures of inaccuracy agree that an agent whose degree of belief function violates the probability axioms should adopt a probabilistic degree of belief function which is more accurate in each possible world. However, these measures may differ in their recommendation as to which particular probability measure the agent should adopt. In fact, for each possible world, following the recommendation of one measure will leave the agent off less accurate according to some other measure. Why then should the epistemic agent move from her non-probabilistic degree of belief function to a probability measure in the first place? Joyce (2009) responds to this question and other objections (e.g. Maher 2002).
2.4 Update Rules
We have discussed how to measure and interpret subjective probabilities, and why degrees of belief should be subjective probabilities. It is of particular epistemological interest how to update subjective probabilities when new information is received. Whereas axioms 1-5 of the probability calculus are synchronic conditions on an agent's degree of belief function, update rules are diachronic conditions that tell us how to revise our subjective probabilities when we receive new information of a certain format. If the new information comes in form of a certainty, probabilism is extended by
Strict Conditionalization
If evidence comes only in form of certainties (that is, propositions of which you become certain), if Pr: A → ℜ is your subjective probability at time t, and if between t and t′ you become certain of A ∈ A and no logically stronger proposition (in the sense that your new probability for A, but for no logically stronger proposition, is 1), then your subjective probability at time t′ should be Pr(·|A).
Strict conditionalization thus says that the agent's new subjective probability for a proposition B after becoming certain of A should equal her old subjective probability for B conditional on A.
Two questions arise. First, why should we update our subjective probabilities according to strict conditionalization? Second, how should we update our subjective probabilities when the new information is of a different format and we do not become certain of a proposition, but merely change our subjective probabilities for various propositions? Jeffrey (1983a) answers the second question by what is now known as Jeffrey conditionalization. The propositions whose (unconditional) probability changes as a result of the evidential experience are called evidential propositions. Intuitively, Jeffrey conditionalization says that the ideally rational epistemic agent should keep fixed her “inferential beliefs”, that is, the probabilities of all hypotheses conditional on any evidential proposition.
Jeffrey Conditionalization.
If evidence comes only in form of new degrees of belief for the elements of a partition, if Pr: A → ℜ is your subjective probability at time t, and if between t and t′ your subjective probabilities in the mutually exclusive and jointly exhaustive propositions Ai ∈ A change to pi ∈ [0,1] with ∑ipi = 1, and the positive part of your subjective probability does not change on any superset of the partition {Ai}, then your subjective probability at time t′ should be Pr′(·) = ∑i Pr(·|Ai)pi.
Jeffrey conditionalization thus says that the agent's new subjective probability for B after changing her subjective probabilities for the elements Ai of a partition to pi should equal the weighted sum of her old subjective probabilities for B conditional on the Ai, where the weights are the new subjective probabilities pi for the elements of the partition.
One answer to the first question is the Lewis-Teller Dutch Book Argument (Lewis 1999, Teller 1973). Its extension to Jeffrey conditionalization is presented in Armendt (1980) and discussed in Skyrms (1987). For more on diachronic coherence see Skyrms (2006). Greaves & Wallace (2006) provide a different argument for strict conditionalization. Other philosophers have provided arguments against strict (and Jeffrey) conditionalization: van Fraassen (1989) holds that rationality does not require the adoption of a particular update rule (but see Hájek 1998 and Kvanvig 1994), and Arntzenius (2003) uses, among others, the “shifting” nature of self-locating beliefs to argue against strict conditionalization as well as against van Fraassen's reflection principle (van Fraassen 1995). The second feature used by Arntzenius (2003), called “spreading”, is independent of self-locating beliefs.
2.5 Ignorance
In subjective probability theory complete ignorance of the epistemic agent with respect to a particular proposition A is modeled by the agent's having a subjective probability of .5 for A as well as its complement W \ A. More generally, an agent with subjective probability Pr is said to be ignorant with respect to the partition {A1, …, An} if and only if Pr(Ai) = 1/n. The principle that requires an ideally rational epistemic agent to equally distribute her subjective probabilities in this fashion whenever, roughly, the agent lacks knowledge of the relevant sort is known as the principle of indifference. It leads to contradictory results if the partition in question is not held fixed (see, for instance, the discussion of Bertrand's paradox in Kneale 1949). A more cautious version of this principle that is also applicable if the partition contains countably infinitely many elements is the principle of maximum entropy. It requires the agent to adopt one of those probability measures Pr as her degree of belief function over (the σ-field generated by) the countable partition {Ai} that maximize the quantity −∑i Pr(Ai) log Pr(Ai). The latter is known as the entropy of Pr with respect to the partition {Ai}. See Paris (1994).
Suppose Sophia has hardly any enological knowledge. Her subjective probability for the proposition that a Schilcher, an Austrian wine specialty, is a white wine might reasonably be .5, as might be her subjective probability that a Schilcher is a red wine. Contrast this with the following case. Sophia knows for sure that a particular coin is fair. That is, Sophia knows for sure that the objective chance of the coin landing heads as well as its objective chance of landing tails each equal .5. Then her subjective probability for the proposition that the coin will land heads on the next toss might reasonably be .5. Although Sophia's subjective probabilities are alike in these two scenarios, there is an important epistemological difference. In the first case a subjective probability of .5 represents complete ignorance. In the second case it represents substantial knowledge about the objective chances. (The principle that, roughly, one's prior subjective probabilities conditional on the objective chances should equal the objective chances is called the principal principle by Lewis 1980.)
Examples like these suggest that subjective probability theory does not provide an adequate account of epistemic states, because it does not allow one to distinguish between ignorance and knowledge about chances. Interval-valued probabilities (Kyburg & Teng 2001, Levi 1980, van Fraassen 1990, Walley 1991) can be seen as a reply to this objection without giving up the probabilistic framework. If the ideally rational epistemic agent knows the objective chances she continues to assign sharp probabilities as usual. However, if the agent is ignorant with respect to a proposition A she will not assign it a subjective probability of .5 (or any other sharp value, for that matter). Rather, she will assign A a whole interval [a, b] ⊆ [0,1] such that she considers any number in [a, b] to be a legitimate subjective probability for A. The size b − a of the interval [a, b] reflects her ignorance with respect to A, that is, with respect to the partition {A, W \ A}. (As suggested by the last remark, if [a, b] is the interval-probability for A, then [1 − b, 1 − a] is the interval-probability for W \ A.) If Sophia were the enological ignoramus that we have previously imagined her to be, she would assign the interval [0,1] to the proposition that a Schilcher is a white wine. If she knows for sure that the coin she is about to toss has an objective chance of .5 of landing heads and she subscribes to the principal principle, [.5,.5] will be the interval she assigns to the proposition that the coin will land heads on the next toss.
Interval-valued probabilities are represented as convex sets of probability measures (a set of probability measures is convex just in case the mixture xPr1(·) + (1 − x)Pr2(·) of any two probability measures Pr1, Pr2 in the set is also in the set, where x is a real number from the unit interval [0,1]). Updating a set of probability measures is done by updating the individual probability measures in the set. Weatherson (2007) further generalizes this model by allowing evidence to delete some probability measures from the original set. The idea is that one may learn not only that various facts obtain (in which case one conditionalizes the various probability measures on the evidence received), but also that various evidential or inferential relationships hold, which are represented by the conditional probabilities of the hypotheses conditional on the data. Just as factual evidence is used to delete worlds, “inferential” evidence is used to delete probability measures. Among others, this allows Weatherson (2007) to deal with one form of the so-called problem of old evidence (Glymour 1980) that is related to the problem of logical omniscience (Garber 1983, Jeffrey 1983b, Niiniluoto 1983).
2.6 Categorical Belief
When epistemologists say that knowledge implies belief (see the entry on epistemology), they use a qualitative notion of belief that does not admit of degrees (except in the trivial sense that there is belief, disbelief, and suspension of judgment). The same is true for philosophers of language when they say that a normal speaker, on reflection, sincerely asserts ‘A’ only if she believes that A (Kripke 1979). This raises the question whether the notion of belief can be reduced to the notion of degree of belief. A simple thesis, known as the Lockean thesis, says that one should believe a proposition A just in case one's degree of belief for A is sufficiently high (‘should’ takes wide scope over ‘just in case’). Of course, the question is which threshold is sufficiently high. We do not want to require that one only believe those propositions whose truth one assigns subjective probability 1 — especially if we follow Carnap (1962) and Jeffrey (2004) and require every reasonable subjective probability to be regular (otherwise we would not be allowed to believe anything except the tautology). We want to take into account our fallibility, the fact that our beliefs often turn out to be false.
Given that degrees of belief are represented as subjective probabilities, this means that the threshold for belief should be less than 1. In terms of subjective probabilities, the Lockean thesis then says that an ideally rational epistemic agent with subjective probability Pr: A → ℜ believes A ∈ A just in case Pr(A) > 1 − ε for some ε ∈ (0,1]. This, however, leads to the lottery paradox (Kyburg 1961, and, much clearer, Hempel 1962) as well as the preface paradox (Makinson 1965). For every threshold ε ∈ (0,1] there is a finite partition {A1, …, An} of A and a reasonable subjective probability Pr: A → ℜ such that Pr(Ai) > 1 − ε for all i = 1, …, n, but Pr(A1∩…∩An) < 1 − ε. For instance, let ε = .02 and consider a lottery with 100 tickets that is known for sure to be fair and such that exactly one ticket will win. Then it is reasonable, for every ticket i = 1, …, 100, to assign a subjective probability of 1/100 to the proposition that ticket i will win. We thus believe of each single ticket that it will lose, because Pr(W \ Ai) = .99 > 1 − .02. Yet we also know for sure that exactly one ticket will win. So Pr(A1∪…∪An) = 1 > 1 − .02. We therefore believe both that at least one ticket will win (A1∪…∪An) as well as of each individual ticket that it will not win (W \ A1, …, W \ An). Together these n+1 beliefs form a belief set that is inconsistent in the sense that its intersection is empty, ∩{A1∪…∪An, W \ A1, …, W \ An} = ∅. Yet consistency (and deductive closure, which is implicit in taking propositions rather than sentences as the objects of belief) have been regarded as the minimal requirements on a belief set ever since Hintikka (1961).
The lottery paradox has led some people to reject the notion of categorical belief altogether (Jeffrey 1970), whereas others have been led to the idea that belief sets need not be deductively closed (Foley 1992; Foley 2009; see also Hawthorne 2004). Still others have turned the analysis on its head and elicit a context-dependent threshold parameter ε from the agent's belief set (Hawthorne and Bovens 1999; Hawthorne 2009). Another view is to take the lottery paradox at face value and postulate two epistemic attitudes towards propositions, viz. beliefs and degrees of beliefs, that are not reducible to each other. Frankish (2004; 2009) defends a particular version of this view (in addition, he distinguishes between a mind, where one unconsciously entertains beliefs, and a supermind, where one consciously entertains beliefs). For further discussion on the relation between categorical belief and probabilistic degrees of belief see Christensen (2004), Kaplan (1996), and Maher (2006).
A further topic that has recently attracted a lot of attention are probabilistic theories of coherence (Bovens & Hartmann 2003, Fitelson 2003, Olsson 2005).
3. Other Accounts
3.1 Dempster-Shafer Theory
The theory of Dempster-Shafer (DS) belief functions (Dempster 1968, Shafer 1976) rejects the claim that degrees of belief can be measured by the epistemic agent's betting behavior. A particular version of the theory of DS belief functions is the transferable belief model (Smets & Kennes 1994). It distinguishes between two mental levels: the credal level, where one entertains and quantifies various beliefs, and the pignistic level, where one uses those beliefs for decision making. Its twofold thesis is that (fair) betting ratios should indeed obey the probability calculus, but that degrees of belief, being different from (fair) betting ratios, need not. It suffices that they satisfy the weaker DS principles. The idea is that whenever one is forced to bet on the pignistic level, the degrees of belief from the credal level are used to calculate (fair) betting ratios that satisfy the probability axioms. These in turn are then used to calculate the agent's expected utility for various acts (Joyce 1999, Savage 1972). However, on the credal level degrees of belief need not obey the probability calculus.
Whereas subjective probabilities are additive (axiom 3), DS belief functions Bel: A → ℜ are only super-additive, i.e., for all propositions A, B in A:
- Bel(A) + Bel(B) ≤ Bel(A∪B) if A∩B = ∅
In particular, the agent's degree of belief for A and her degree of belief for W \ A need not sum to 1.
What does it mean to say that Sophia's degree of belief that tomorrow it will be sunny in Vienna equals .55, if her degrees of belief are represented by a DS belief function Bel: A → ℜ? According to one interpretation (Haenni & Lehmann 2003), the number Bel(A) represents the strength with which A is supported by the agent's knowledge or belief base. It may well be that this base neither supports A nor its complement W \ A. Recall the supposition that Sophia has hardly any enological knowledge. Under that assumption her knowledge or belief base will neither support the proposition Red that a Schilcher is a red wine nor will it support the proposition White that a Schilcher is a white wine. However, due to a different aspect of her enological ignorance (namely that she does not know that there are wines, namely rosés, which are neither red nor white), Sophia may well be certain that a Schilcher is either a red wine or a white wine. Hence Sophia's DS belief function Bel will be such that Bel(Red) = Bel(White) = 0 while Bel(Red∪White) = 1. On the other hand, Sophia knows for sure that the coin she is about to toss is fair. Hence her Bel will be such that Bel(H) = Bel(T) = .5 as well as Bel(H∪T) = 1. Thus we see that the theory of DS belief functions can distinguish between uncertainty and one form of ignorance. Indeed,
I({Ai}) = 1 − Bel(A1) − … − Bel(An) − …
can be seen as a measure of the agent's ignorance with respect to the countable partition {Ai} (the Ai may, for instance, be the values of a random variable such as the price of a bottle of Schilcher in Vienna on Aug 8, 2008).
Figuratively, a proposition A divides the agent's knowledge or belief base into three mutually exclusive and jointly exhaustive parts: a part that speaks in favor of A, a part that speaks against A (i.e., in favor of W \ A), and a part that neither speaks in favor of nor against A. Bel(A) quantifies the part that supports A, Bel(W \ A) quantifies the part that supports W \ A, and I({A, W \ A}) = 1 − Bel(A) − Bel(W \ A) quantifies the part that neither supports A nor W \ A. Formally this is spelt out in terms of a (normalized) mass function on A, a function m: A → ℜ such that for all propositions A in A:
- m(A) ≥ 0,
- m(∅) = 0 (normalization), and
- ∑B ∈ A m(B) = 1
A (normalized) mass function m: A → ℜ induces a DS belief function Bel: A → ℜ by defining for each A in A,
Bel(A) = ∑B ⊆ A m(B).
The relation to subjective probabilities can now be stated as follows. Subjective probabilities require the epistemic agent to divide her knowledge or belief base into two mutually exclusive and jointly exhaustive parts: one that speaks in favor of A, and one that speaks against A. That is, the neutral part has to be distributed among the positive and negative parts. Subjective probabilities can thus be seen as DS belief functions without ignorance. (See Pryor (manuscript, Other Internet Resources) for a model of epistemic states that comprises probability theory and Dempster-Shafer theory as special cases.)
A DS belief function Bel: A → ℜ induces a Dempster-Shafer plausibility function P: A → ℜ, where for all A in A,
P(A) = 1 − Bel(W \ A).
Degrees of plausibility quantify that part of the agent's knowledge or belief base which is compatible with A, i.e., the part that supports A and the part that supports neither A nor W \ A. In terms of the (normalized) mass function m inducing Bel this means that
P(A) = ∑B∩A ≠ ∅ m(B).
If and only if Bel(A) and Bel(W \ A) sum to less than 1, P(A) and P(W \ A) sum to more than 1. For an overview see Haenni (2009).
The theory of DS belief functions is more general than the theory of subjective probability in the sense that the latter requires degrees of belief to be additive, while the former merely requires them to be super-additive. In another sense, though, the converse is true. The reason is that DS belief functions can be represented as convex sets of probabilities (Walley 1991). As not every convex set of probabilities can be represented as a DS belief function, sets of probabilities provide the most general framework we have come across so far. An even more general framework is provided by Halpern's plausibility measures (Halpern 2003). These are functions Pl: A → ℜ such that for all A, B in A:
- Pl(∅) = 0,
- Pl(W) = 1,
- Pl(A) ≤ Pl(B) if A ⊆ B
In fact, these are only the special cases of real-valued plausibility measures. While it is fairly uncontroversial that an ideally rational epistemic agent's degree of belief function should obey Halpern's plausibility calculus, it is questionable whether his minimal principles are all there is to the rationality of degrees of belief. The resulting epistemology is, in any case, very thin.
3.2 Possibility Theory
Possibility theory (Dubois & Prade 1988) is based on fuzzy set theory (Zadeh 1978). According to the latter theory, an element need not belong to a given set either completely or not at all, but may be a member of the set to a certain degree. For instance, Sophia may belong to the set of black haired women to a degree of .55, because her hair, although black, is sort of brown as well (I can assure you that she belongs to the set of beautiful women to degree 1). This is represented by a membership function μB: W → [0,1], where μB(w) is the degree of membership to which woman w ∈ W belongs to the set of black haired woman B.
Furthermore, the degree μW \ B(Sophia) to which Sophia belongs to the set W \ B of women who do not have black hair equals 1 − μB(Sophia). Moreover, if μY: W → [0,1] is the membership function for the set of young women, then the degree of membership to which Sophia belongs to the set B∪Y of black haired or young women is given by
μB∪Y(Sophia) = max{μB(Sophia), μY(Sophia)}.
Similarly, the degree of membership to which Sophia belongs to the set B∩Y of black haired young women is given by
μB∩Y(Sophia) = min{μB(Sophia), μY(Sophia)}.
mB∩Y(Sophia) is interpreted as the degree to which the vague statement “Sophia is a black haired woman” is true (for vagueness see Williamson 1994 as well as the entry on vagueness; Field forthcoming discusses uncertainty due to vagueness in a probabilistic setting). Degrees of truth belong to philosophy of language. They do not (yet) have anything to do with degrees of belief, which belong to epistemology. In particular, note that degrees of truth are usually considered to be truth functional (the truth value of a compound statement such as A∧B is a function of the truth values of its constituent statements A, B; that is, the truth values of A and B determine the truth value of A∧B). Degrees of belief, on the other hand, are hardly ever considered to be truth functional. For instance, probabilities are not truth functional, because the probability of A∩B is not determined by the probability of A and the probability of B. That is, there is no function f such that for all probability spaces <W, A, Pr> and all propositions A, B in A: Pr(A∩B) = f(Pr(A), Pr(B)).
Suppose someone says that Sophia is tall. How tall is a tall woman? Is a woman with a height of 5′9″ tall? Or does a woman have to be at least 5′10″ in order to be tall? Although you know that Sophia is tall, your knowledge is incomplete due to the vagueness of the term ‘tall’. Here possibility theory enters by equipping you with a (normalized) possibility distribution, a function π: W → [0,1] with π(w) = 1 for at least one w ∈ W. The motivation for the latter requirement is that at least (in fact, exactly) one possibility is the actual possibility, and hence at least one possibility must be maximally possible. Such a possibility distribution π: W → [0,1] on the set of possibilities W is extended to a possibility measure Π: A → ℜ on the field A over W by defining for each A in A,
Π(∅) = 0, Π(A) = sup{π(w): w ∈ A}.
This entails that possibility measures Π: A → ℜ are maxitive (and hence sub-additive), i.e., for all A, B ∈ A:
- Π(A∪B) = max{Π(A), Π(B)}.
The idea is, roughly, that a proposition is at least as possible as each of the possibilities it comprises, and no more possible than the “most possible” possibility either. Sometimes, though, there is no most possible possibility (i.e., the supremum is no maximum). For instance, that is the case when the degrees of possibility are 1/2, 3/4, 7/8, …, (2n − 1)/2n, … In this case the degree of possibility for the proposition is the smallest number which is at least as great as all the degrees of possibilities of its elements. In our example this is 1. (As will be seen below, this is the main formal difference between possibility measures and unconditional ranking functions.)
We can define possibility measures without recourse to an underlying possibility distribution as functions Π: A → ℜ such that
- Π(∅) = 0,
- Π(W) = 1, and
- Π(A∪B) = max{Π(A), Π(B)}.
It is important to note, though, that the last clause is not well-defined for disjunctions or unions of infinitely many propositions (in this case one would have to use the supremum operation sup instead of the maximum operation max). The dual notion of a necessity measure Ν: A → ℜ is defined for all A in A by
Ν(A) = 1 − Π(W \ A).
This implies that
Ν(A∩B) = min{Ν(A), Ν(B)}.
The latter equation can be used to start with necessity measures as primitive. Define them as functions Ν: A → ℜ such that
Ν(∅) = 0, Ν(W) = 1, Ν(A∩B) = min{Ν(A), Ν(B)}.
Then possibility measures Π: A → ℜ are obtained by the equation:
Π(A) = 1 − Ν(W \ A).
Although the agent's epistemic state in possibility theory is completely specified by either Π or Ν, the agent's epistemic attitude towards a particular proposition A is only jointly specified by Π(A) and Ν(A). The reason is that, in contrast to probability theory, Π(W \ A) is not determined by Π(A). Thus, degrees of possibility (as well as degrees of necessity) are not truth functional either. The same is true for DS belief and plausibility functions.
In our example, let WH be the set of values of the random variable H = Sophia's body height in inches between 0″ and 199″, WH = {0, …, 199}. πH: WH → [0,1] is your possibility distribution. It is supposed to represent your epistemic state concerning Sophia's height, which contains the knowledge that she is tall. For instance, your πH might be such that πH(n) = 1 for any natural number n ∈ [60,72] ⊆ W. In this case your degree of possibility for the proposition that Sophia is at least 5′9″ is ΠH(H ≥ 69) = sup{πH(n): n ≥ 69} = 1.
The connection to fuzzy set theory now is that your possibility distribution πH: WH → [0,1], which is based on the knowledge that Sophia is tall, can be interpreted as the membership function μT: WH → [0,1] of the set of tall woman. So the epistemological thesis of possibility theory is that your degree of possibility for the proposition that Sophia is 5′9″ given the vague and hence incomplete knowledge that Sophia is tall should equal the degree of membership to which a 5′9″ tall woman belongs to the set of tall woman. In more suggestive notation,
πH(H = n | T) = μT(n).
Let us summarize the accounts we have dealt with so far. Subjective probability theory requires degrees of belief to be additive. An ideally rational epistemic agent's subjective probability Pr: A → ℜ is such that for any A, B in A with A∩B = ∅:
Pr(A) + Pr(B) = Pr(A∪B)
The theory of DS belief functions requires degrees of belief to be super-additive. An ideally rational epistemic agent's DS belief function Bel: A → ℜ is such that for any A, B in A with A∩B = ∅:
Bel(A) + Bel(B) ≤ Bel(A∪B)
Possibility theory requires degrees of belief to be maxitive and hence sub-additive. An ideally rational epistemic agent's possibility measure Π: A → ℜ is such that for any A, B in A:
Π(A) + Π(B) ≥ max{Π(A), Π(B)} = Π(A∪B)
All of these functions are special cases of real-valued plausibility measures Pl: A → ℜ, which are such that for all A, B in A:
Pl(A) ≤ Pl(B) if A ⊆ B
We have seen that each of these accounts provides an adequate model for some epistemic situation (plausibility measures do so trivially). We have further noticed that subjective probabilities do not give rise to a notion of categorical belief that is consistent and deductively closed (unless categorical belief is identified with a subjective probability of 1). Therefore the same is true for the more general DS belief functions and plausibility measures. It has to be noted, though, that Roorda provides a definition of belief in terms of sets of probabilities (see Roorda 1995, listed in the Other Internet Resources section). (As will be mentioned in the next section, there is a notion of belief in possibility theory that is consistent and deductively closed in a finite sense.)
Moreover, we have seen arguments for the thesis that degrees of belief should obey the probability axioms. Smets (2002) tries to justify the corresponding thesis for DS belief functions. To the best of my knowledge nobody has yet published an argument for the thesis that degrees of belief should be plausibility or possibility measures, respectively (in the sense that all and only plausibility respectively possibility measures are reasonable degree of belief functions). However, there exists such an argument for ranking functions, which are formally similar to possibility measures. Ranking functions also give rise to a notion of belief that is consistent and deductively closed (indeed, this very feature is the starting point for the argument that epistemic states should obey the ranking calculus). They are the topic of the next section.
3.3 Ranking Theory
Subjective probability theory as well as the theory of DS belief functions take the objects of belief to be propositions. Possibility theory does so only indirectly, though possibility measures on a field of propositions A can also be defined without recourse to a possibility distribution on the underlying set W of possibilities.
A possibility w in W is a complete and consistent description of the world relative to the expressive power of W. W may contain just two possibilities: according to w1 tomorrow it will be sunny in Vienna, according to w2 it will not. On the other end of the spectrum, W may comprise grand possible worlds à la Lewis (1986). (For more see the forthcoming entry on possible worlds.)
We usually do not know for sure which one of the possibilities in W corresponds to the actual world. Otherwise these possibilities would not be genuine possibilities for us, and our degree of belief function would collapse into the truth value assignment corresponding to the actual world. However, to say that we do not know which possibility it is that corresponds to the actual world does not mean that all possibilities are on a par. Some of them will be really far-fetched, while others will seem to be more reasonable candidates for the actual possibility.
This gives rise to the following consideration. We can partition the set of possibilities, that is, form sets of possibilities that are mutually exclusive and jointly exhaustive. Then we can order the cells of this partition according to their plausibility. The first cell in this ordering contains the possibilities that we take to be the most reasonable candidates for the actual possibility. The second cell contains the possibilities which we take to be the second most reasonable candidates. And so on.
If you are still equipped with your possibility distribution from the preceding section you can use your degrees of possibility for the various possibilities to obtain such an ordered partition. Note, though, that an ordered partition — in contrast to your possibility distribution — contains no more than ordinal information. While your possibility distribution enables you to say how possible you take a particular possibility to be, an ordered partition only allows you to say that one possibility w1 is more plausible than another possibility w2. In fact, an ordered partition does not even enable you to express that the difference between your plausibility for w1 (say, tomorrow the temperature in Vienna will be between 70°F and 75°F) and for w2 (say, tomorrow the temperature in Vienna will be between 75°F and 80°F) is smaller than the difference between your plausibility for w2 and for the far-fetched w3 (say, tomorrow the temperature in Vienna will be between 120°F and 125°F).
This takes us directly to ranking theory (Spohn 1988; 1990), which goes one step further. Rather than merely ordering the possibilities in W, a pointwise ranking function κ: W → N∪{∞} additionally assigns natural numbers from N∪{∞} to the cells of possibilities. These numbers represent the grades of disbelief you assign to the various (cells of) possibilities in W. The result is a numbered partition of W,
κ−1(0), κ−1(1), κ−1(2), …, κ−1(n) = {w ∈ W: κ(w) = n}, … κ−1(∞).
The first cell κ−1(0) contains the possibilities which are not disbelieved (which does not mean that they are believed). The second cell κ−1(1) is the set of possibilities which are disbelieved to degree 1. And so on. It is important to note that, except for κ−1(0), the cells κ−1(n) may be empty, and so would not appear at all in the corresponding ordered partition. κ−1(0) must not be empty, though. The reason is that one cannot consistently disbelieve everything.
More precisely, a function κ: W → N∪{∞} from a set of possibilities W into the set of natural numbers extended by ∞, N∪{∞}, is a pointwise ranking function just in case κ(w) = 0 for at least one w in W, i.e., just in case κ−1(0) ≠ ∅. The latter requirement says that you should not disbelieve every possibility. It is justified, because you know for sure that one possibility is actual. A pointwise ranking function κ: W → N∪{∞} on W induces a ranking function ρ: A → N∪{∞} on a field A of propositions over W by defining for each A in A,
ρ(A) = min{κ(w): w ∈ A} (= ∞ if A = ∅).
This entails that ranking functions ρ:A → N∪∞} are (finitely) minimitive (and hence super-additive), i.e., for all A, B in A,
- ρ(A∪B) = min{ρ(A), ρ(B)}.
As in the case of possibility theory, (finitely minimitive and unconditional) ranking functions can be directly defined on a field A of propositions over a set of possibilities W as functions ρ: A → N∪{∞} such that for all A, B in A:
- ρ(∅) = ∞,
- ρ(W) = 0, and
- ρ(A∪B) = min{ρ(A), ρ(B)}
The triple <W, A, ρ> is a (finitely minimitive) ranking space. Suppose A is closed under countable/complete intersections (and thus a σ-/γ-field). Suppose further that ρ additionally satisfies, for all countable/possibly uncountable B ⊆ A,
ρ(∪B) = min{ρ(A): A ∈ B}.
Then ρ is a countably/completely minimitive ranking function, and <W, A, ρ> is a σ- or countably/γ- or completely minimitive ranking space. Finally, a ranking function ρ on A is regular just in case ρ(A) < ∞ for every non-empty or consistent proposition A in A. For more see Huber (2006), which discusses under which conditions ranking functions on fields of propositions induce pointwise ranking functions on the underlying set of possibilities.
Let us pause for a moment. The previous paragraphs introduce a lot of terminology for something that seems to add only little to what we have already discussed. Let the necessity measures of possibility theory assign natural instead of real numbers in the unit interval to the various propositions so that ∞ instead of 1 represents maximal necessity/possibility. The axioms for necessity measures then become
Ν(∅) = 0, Ν(W) = ∞ (instead of 1), Ν(A∩B) = min{Ν(A), Ν(B)}.
Now think of the rank of a proposition A as the degree of necessity of its negation W \ A, ρ(A) = Ν(W \ A). Seen this way, finitely minimitive ranking functions are a mere terminological variation of necessity measures, for
ρ(∅) = Ν(W) = ∞ ρ(W) = Ν(∅) = 0 ρ(A∪B) = Ν((W \ A)∩(W \ B)) = min{Ν(W \ A), Ν(W \ B)} = min{ρ(A), ρ(B)}
(If we take necessity measures as primitive rather than letting them be induced by possibility measures, and if we continue to follow the rank-theoretic policy of adopting a well-ordered range, we can obviously also define countably and completely minimitive necessity measures.) Of course, the fact that (finitely minimitive and unconditional) ranking functions and necessity measures are formally alike does not mean that their interpretations are the same.
The latter is the case, though, when we compare ranking functions and Shackle's degrees of potential surprise (Shackle 1949; 1969). (These degrees of potential surprise have made their way into philosophy mainly through the work of Isaac Levi. See Levi 1967a; 1978.) So what justifies devoting a whole section to ranking functions?
Shackle's theory lacks a notion of conditional potential surprise. (Shackle 1969, 79ff, seems to assume a notion of conditional potential surprise as primitive that appears in his axiom 7. This axiom further relies on a connective that behaves like conjunction except that it is not commutative and is best interpreted as “A followed by B”. Axiom 7, in its stronger version from p. 83, seems to say that the degree of potential surprise of “A followed by B” is the greater of the degree of potential surprise of A and the degree of potential surprise of B given A, i.e., ς(A followed by B) = max{ς(A), ς(B|A)} where ς is the measure of potential surprise. Spohn to appear, sct. 4.1, also discusses Shackle's struggle with the notion of conditional potential surprise.)
Possibility theory, on the other hand, offers two notions of conditional possibility (Dubois & Prade 1988). The first notion of conditional possibility is obtained by the equation
Π(A∩B) = min{Π(A), Π(B|A)}.
It is mainly motivated by the desire to have a notion of conditional possibility that also makes sense if possibility does not admit of degrees, but is a merely comparative notion. The second notion of conditional possibility is obtained by the equation
Π(A∩B) = Π(A)·Π(B||A).
The inspiration for this notion seems to come from probability theory. While none of these two notions is the one we have in ranking theory, Spohn (2009), relying on Halpern (2003), shows that by adopting the second notion of conditional possibility one can render possibility theory isomorphic to a real-valued version of ranking theory.
For standard ranking functions with a well-ordered range conditional ranks are defined as follows. The conditional ranking function ρ(·|·): A×A → N∪{∞} on A (based on the unconditional ranking function ρ on A) is defined for all pairs of propositions A, B in A with A ≠ ∅ by
ρ(A|B) = ρ(A∩B) − ρ(B),
where ∞ − ∞ = 0. Further stipulating ρ(∅|B) = ∞ for all B in A guarantees that ρ(·|B): A → N∪{∞} is a ranking function, for every B in A. It would, of course, also be possible to take conditional ranking functions ρ(·, given ·): A×A → N∪{∞} as primitive and define (unconditional) ranking functions in terms of them as ρ(A) = ρ(A, given W) for all propositions A in A.
The number ρ(A) represents the agent's degree of disbelief for the proposition A. If ρ(A) > 0, the agent disbelieves A to a positive degree. Therefore, on pain of inconsistency, she cannot also disbelieve W \ A to a positive degree. In other words, for every proposition A in A, at least one of A, W \ A has to be assigned rank 0. If ρ(A) = 0, the agent does not disbelieve A to a positive degree. This does not mean, however, that she believes A to a positive degree − the agent may suspend judgment and assign rank 0 to both A and W \ A. So belief in a proposition is characterized by disbelief in its negation.
For each ranking function ρ: A → N∪{∞} we can define a corresponding belief function β: A → Z∪{∞}∪{−∞} that assigns positive numbers to those propositions that are believed, negative numbers to those propositions that are disbelieved, and 0 to those propositions with respect to which the agent suspends judgment:
β(A) = ρ(W \ A) − ρ(A)
Each ranking function ρ: A → N∪{∞} induces a belief set
B = {A ∈ A: ρ(W \ A) > 0} = {A ∈ A: ρ(W \ A) > ρ(A)} = {A ∈ A: β(A) > 0}.
B is the set of all propositions the agent believes to some positive degree, or equivalently, whose complements she disbelieves to a positive degree. The belief set B induced by a ranking function ρ is consistent and deductively closed (in the finite sense). The same is true for the belief set induced by a possibility measure Π:A → ℜ,
BΠ = {A ∈ A: Π(W \ A) < 1} = {A ∈ A: Ν(A) > 0}.
If ρ is a countably/completely minimitive ranking function, the belief set B induced by ρ is consistent and deductively closed in the following countable/complete sense: ∩C ≠ ∅ for every countable/uncountable C ⊆ B; and A ∈ B whenever ∩C ⊆ A for some countable/uncountable C ⊆ B and any A ∈ A. Ranking theory thus offers a link between belief and degrees of belief that is preserved when we move from the finite to the countably or uncountably infinite case. As shown by the example in Section 3.2, this is not the case for possibility theory. (Of course, as indicated above, the possibility theorist can copy ranking theory by taking necessity measures as primitive and by adopting a well-ordered range).
Much as for subjective probabilities, there are rules for updating one's epistemic state represented by a ranking function. In case the new information comes in form of a certainty, ranking theory's counterpart to probability theory's strict conditionalization is
Plain Conditionalization.
If evidence comes only in form of certainties, if ρ: A → N∪{∞} is your ranking function at time t, and if between t and t′ you become certain of A ∈ A and no logically stronger proposition (in the sense that your new rank for W \ A, but no logically weaker proposition, is ∞), then your ranking function at time t′ should be ρ(·|A).
If the new information merely changes your ranks for various propositions, ranking theory's counterpart to probability theory's Jeffrey conditionalization is
Spohn Conditionalization.
If evidence comes only in form of new grades of disbelief for the elements of a partition, if ρ: A → N∪{∞} is your ranking function at time t, and between t and t′ your ranks in the mutually exclusive and jointly exhaustive propositions Ai ∈ A change to ni ∈ N∪{∞} with mini ni = 0, and the finite part of your ranking function does not change on any superset of the partition {Ai}, then your ranking function at time t′ should be ρ'(·) = mini{ρ(·|Ai) + ni}.
As the reader will have noticed by now, whenever we substitute 0 for 1, ∞ for 0, min for ∑, ∑ for ∏, and > for <, a true statement about probabilities almost always turns into a true statement about ranking functions. (There are but a few known exceptions to this transformation. Spohn 1994 mentions one.) For a comparison of probability theory and ranking theory see Spohn (2009, sct. 3).
Two complaints about Jeffrey conditionalization carry over to Spohn conditionalization. First, Jeffrey conditionalization is not commutative (Levi 1976b). The same is true of Spohn conditionalization. Second, any two regular probability measures can be related to each other via Jeffrey conditionalization (by letting the evidential partition consist of the set of singletons {w} containing the possibilities w in W). The same is true of any two regular ranking functions and Spohn conditionalization. Therefore, so the complaint goes, these rules are empty as normative constraints.
The first complaint misfires, because both Jeffrey and Spohn conditionalization are result- rather evidence-oriented: the parameters pi and ni characterize the resulting degree of (dis)belief in Ei rather than the amount by which the evidence received between t and t′ boosts or lowers the degree of (dis)belief in Ei. Therefore these parameters depend on both the prior epistemic states Pr and ρ, respectively, and the evidence received between t and t′. Evidence first shifting E from p to p′ and then to p″ is not a rearrangement of evidence first shifting E from p to p″ and then to p′. Field (1978) presents a probabilistic/rank-theoretic update rule that is evidence-oriented in the sense of characterizing the evidence as such, independently of the prior epistemic state. These update rules are commutative. Shenoy (1991) presents a rank-theoretic update rule that is evidence-oriented in this sense. These two update rules are commutative.
The second complaint misfires, because it confuses input and output: Jeffrey conditionalization does not rule out any evidential input of the appropriate format, just as it does not rule out any prior epistemic state not already ruled out by the probability calculus. The same is true of Spohn conditionalization and the ranking calculus. That does not mean that these rules are empty as normative constraints, though. On the contrary, for each admissible prior epistemic state and each admissible evidential input there is only one posterior epistemic state not ruled by Jeffrey (Spohn) conditionalization.
One reason why an epistemic agent's degrees of belief should obey the probability calculus is that otherwise she is vulnerable to a Dutch Book (standard version) or an inconsistent evaluation of the fairness of bets (depragmatized version). For similar reasons she should update her subjective probability according to strict or Jeffrey conditionalization, depending on the format of the new information. Why should grades of disbelief obey the ranking calculus? And why should an epistemic agent update her ranking function according to plain or Spohn Conditionalization?
The answers to these questions require a bit of terminology. An epistemic agent's degree of entrenchment for a proposition A is the number of “independent and minimally positively reliable” information sources saying A that it takes for the agent to give up her disbelief that A. If the agent does not disbelieve A to begin with, her degree of entrenchment for A is 0. If no finite number of information sources is able to make the agent give up her disbelief that A, her degree of entrenchment for A is ∞. Suppose we want to determine Sophia's degree of entrenchment for the proposition that Vienna is the capital of Austria. This can be done by putting her on, say, the Stephansplatz and by counting the number of people passing by and telling her that Vienna is the capital of Austria. Her degree of entrenchment for the proposition that Vienna is the capital of Austria equals n precisely if she stops disbelieving that Vienna is the capital of Austria after n people have passed by and told her it is. The relation between these operationally defined degrees of entrenchment and the theoretical grades of disbelief is identical to the relation between betting ratios and degrees of belief: under suitable conditions (when the information sources are independent and minimally positively reliable) the former can be used to measure the latter. Most of the time the conditions are not suitable, though. In section 2.2 primitivism seemed to be the only plausible game in town. In the present case “going hypothetical” (Eriksson & Hájek 2007) is more promising: the agent's grade of disbelief in A is the number of information sources saying A that it would take for her to give up her categorical disbelief that A, if those sources were independent and minimally positively reliable.
Now we are in the position to say why degrees of disbelief should obey the ranking calculus. They should do so, because an agent's belief set is and will always be consistent and deductively closed in the finite/countable/complete sense just in case her entrenchment function is a finitely/countably/completely minimitive ranking function and, depending on the format of the evidence, the agent updates according to plain or Spohn conditionalization (Huber 2007b).
It follows that the above notion of conditional ranks is the only good notion for standard ranking functions with a well-ordered domain: plain and Spohn conditionalization depend on the notion of conditional ranks, and the theorem does not hold if we replace that notion by another one. Furthermore, one reason for adopting standard ranking functions with a well-ordered domain is that the notion of degree of entrenchement makes only sense for natural (or ordinal) numbers, because one has to count the independent and minimally positively reliable information sources. The seemingly small differences between possibility theory and ranking theory thus turn out to be crucial.
With the possible exception of decision making (see, however, Giang & Shenoy 2000), it seems we can do everything with ranking functions that we can do with probability measures. In contrast to probability theory, ranking theory also has a notion of categorical belief that is vital if we want to stay in tune with traditional epistemology. In addition, this allows for rank-theoretic theories of belief revision and of nonmonotonic reasoning, which are the topic of the final two sections.
3.4 Belief Revision Theory
We have moved from degrees of belief to belief, and found ranking theory to provide a link between these two notions. While some philosophers (most probabilists, e.g. Jeffrey 1970) hold the view that degrees of belief are more basic than beliefs, others adopt the opposite view. This opposite view is generally adopted in traditional epistemology, which is mainly concerned with the notion of knowledge and its tripartite definition as justified true belief. Belief in this sense comes in three “degrees”: the ideally rational epistemic agent either believes A, or else she believes W \ A and thus disbelieves A, or else she believes neither A nor W \ A and thus suspends judgment with respect to A. Ordinary epistemic agents sometimes believe both A and W \ A, but we assume that they should not do so, and hence ignore this case.
According to this view, an agent's epistemic state is characterized by the set of propositions she believes, her belief set. Such a belief set is required to be consistent and deductively closed (Hintikka 1961 and the entry on see the entry on epistemic logic). Here a belief set is usually represented as a set of sentences from a language L rather than as a set of propositions. The question addressed by belief revision theory (Alchourrón & Gärdenfors & Makinson 1985, Gärdenfors 1988, Gärdenfors & Rott 1995) is how an ideally rational epistemic agent should revise her belief set B ⊆ L if she learns new information in the form of a sentence α ∈ L. If α is consistent with B in the sense that ¬α is not derivable from B, the agent should simply add α to B and close this set under (classical) logical consequence. In this case her new belief set, i.e., her old belief set B revised by the new information α, B ∗ α, is the set of logical consequences of B∪{α}, B ∗ a = Cn(B∪{α}) = {β ∈ L: B∪{α} ⊢ β}.
Things get interesting when the new information α contradicts the old belief set B. The basic idea is that the agent's new belief set B ∗ α should contain the new information α and as many of the old beliefs in B as is allowed by the requirement that the new belief set be consistent and deductively closed. To state this more precisely, let us introduce the notion of a contraction. To contract a statement α from a belief set B is to give up the belief that α is true, but to keep as many of the remaining beliefs from B while ensuring consistency and deductive closure. Where B ÷ α is the agent's new belief set after contracting her old belief set B by α, the A(lchourrón)G(ärdenfors)M(akinson) postulates for contraction ÷ can be stated as follows. (Note that ∗ as well as ÷ are functions from ℘(L)×L into ℘(L).)
For every set of sentences B ⊆ L and any sentences α, β ∈ L:
| [÷1] | If B = Cn(B), then B ÷ α = Cn(B ÷ α) | Deductive Closure |
| [÷2] | B ÷ α ⊆ B | Inclusion |
| [÷3] | If α ∉ Cn(B), then B ÷ α = B | Vacuity |
| [÷4] | If α ∉ Cn(∅), then α ∉ Cn(B ÷ α) | Success |
| [÷5] | If Cn({α}) = Cn({β}), then B ÷ α = B ÷ β | Preservation |
| [÷6] | If B = Cn(B), then B ⊆ Cn((B ÷ α)∪{α}) | Recovery |
| [÷7] | If B = Cn(B), then (B ÷ α)∩(B ÷ β) ⊆ B ÷ (α∧β) | |
| [÷8] | If B = Cn(B) and α ∉ B ÷ (α∧β), then B ÷ (α∧β) ⊆ B ÷ α |
÷1 says that the contraction of B by α, B ÷ α, should be deductively closed, if B is deductively closed. ÷2 says that a contraction should not give rise to new beliefs not previously held. ÷3 says that the epistemic agent should not change her old beliefs when she gives up a sentence she does not believe to begin with. ÷4 says that, unless α is tautological, the agent should really give up her belief that α is true if she contracts by α. ÷5 says that the particular formulation of the sentence the agent gives up should not matter; in other words, the objects of belief should really be propositions rather than sentences. ÷6 says the agent should recover her old beliefs if she first contracts by α and then adds α again, provided B is deductively closed. According to ÷7 the agent should not give up more beliefs when contracting by α∧β than the ones she gives up when she contracts by α alone or by β alone. ÷8 finally requires the agent not to give up more beliefs than necessary: if the agent already gives up α when she contracts by α∧β, she should not give up more than she gives up when contracting by α alone. Rott (2001) discusses many further principles and variations of the above.
Given the notion of a contraction we can now state what the agent's new belief set, i.e., her old belief set B revised by the new information α, B ∗ α, should look like. First, the agent should clear B to make it consistent with α. That is, the agent first should contract B by ¬α. Then she should simply add α and close under (classical) logical consequence. This gives us the agent's new belief set B ∗ α, her old belief set B revised by α. The recipe just described is known as the Levi identity:
B ∗ α = Cn((B ÷ ¬α)∪{α})
Revision ∗ defined in this way satisfies a corresponding list of properties. For every set of sentences B ⊆ L and any sentences α, β ∈ L (where the contradictory sentence ⊥ can be defined as the negation of the tautological sentence ⊤, i.e., ¬⊤):
| [∗1] | B ∗ α = Cn(B ∗ α) |
| [∗2] | α ∈ B ∗ α |
| [∗3] | If ¬α ∉ Cn(B), then B ∗ α = Cn(B∪{α}) |
| [∗4] | If ¬α ∉ Cn(∅), then ⊥ ∉ B ∗ α |
| [∗5] | If Cn({α}) = Cn({α}), then B ∗ α = B ∗ β |
| [∗6] | If B = Cn(B), then (B ∗ α)∩B = B ÷ ¬α |
| [∗7] | If B = Cn(B), then B ∗ (α∧β) ⊆ Cn(B ∗ α ∪ {β}) |
| [∗8] | If B = Cn(B) and ¬β ∉ B ∗ α, then Cn(B ∗ α ∪ {β}) ⊆ B ∗ (α∧β) |
In standard belief revision theory the new information is always part of the new belief set. Non-prioritized belief revision relaxes this requirement (Hansson 1999). The idea is that the epistemic agent might consider the new information to be too implausible to be added and decide to reject it; or she might add only a sufficiently plausible part of the new information; or she might add the new information and then check for consistency, which makes her give up part or all of the new information again, because her old beliefs turn out to be more entrenched.
The notion of entrenchment provides the connection to degrees of belief. In order to decide which part of her belief set she wants to give up, belief revision theory equips the epistemic agent with an entrenchment ordering. Technically, this is a relation ≼ on L (i.e., ≼ ⊆ L) such that for all α, β, γ in L:
| [≼1] | If α ≼ β and β ≼ γ, then α ≼ γ | Transitivity |
| [≼2] | If α ⊢ β, then α ≼ β | Dominance |
| [≼3] | α ≼ α∧β or β ≼ α∧β | Conjunctivity |
| [≼4] | If ⊥ ∉ Cn(B), then [α ∉ B if and only if for all β in L: α ≼ β] | Minimality |
| [≼5] | If for all α in L: α ≼ β, then β ∈ Cn(∅) | Maximality |
B is a fixed set of background beliefs. Given an entrenchment ordering
≼ on L and letting α
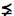 β hold just in case α
≼
β and β ⋠
α, we can define a revision operator ∗ as follows:
β hold just in case α
≼
β and β ⋠
α, we can define a revision operator ∗ as follows:
B ∗ α = {β ∈ B: ¬α
Then one can prove the following representation theorem:
Theorem 1:
Let L be a language, let B ⊆ L be a set of sentences, and let α ∈ L be a sentence. Each entrenchment ordering ≼ on L induces a revision operator ∗ on L satisfying ∗1 – ∗8 by defining B ∗ α = {β ∈ B: ¬α
It is, however, fair to say that belief revision theorists distinguish between degrees of belief and entrenchment. Entrenchment, so they say, characterizes the agent's unwillingness to give up a particular categorical belief, which may be different from her degree of belief for the respective sentence or proposition. Although this distinction seems to violate Occam's razor by unnecessarily introducing an additional epistemic level, it corresponds to Spohn's parallelism (Spohn 2009, sct. 3) between subjective probabilities and ranking functions as well as Stalnaker's stance in his (1996, sct. 3). Weisberg (forthcoming) offers a similar distinction.
If the agent's epistemic state is represented by a ranking function ρ (on a field of propositions over the set of models ModL for the language L, as explained in section 1.3) the ordering ≼ρ that is defined for all α, β in L by
α ≼ρ β if and only if ρ(Mod(¬α)) ≤ ρ(Mod(¬β))
is an entrenchment ordering for B = {α ∈ L: ρ(Mod(¬α)) > 0}. Ranking theory thus covers AGM belief revision theory as a special case (Rott 2009 defines, among others, entrenchment orderings and ranking functions for beliefs as well as for disbeliefs and non-beliefs). It is important is to see how ranking theory goes beyond AGM belief revision theory. In the latter theory the agent's prior epistemic state is characterized by a belief set B together with an entrenchment ordering ≼. If the agent receives new information in the form of a proposition A, the entrenchment ordering is used to turn the old belief set into a new one, viz. B ∗ A. The agent's posterior epistemic state is thus characterized by a belief set only. The entrenchment ordering itself is not updated. Therefore AGM belief revision theory cannot handle iterated belief changes. To the extent that belief revision is not simply a one step process, AGM belief revision theory is thus no theory of belief revision at all. (The analogous situation in terms of subjective probabilities would be to characterize the agent's prior epistemic state by a set of propositions together with a subjective probability measure, and to use that measure to update the set of propositions without ever updating the probability measure itself.)
In ranking theory the agent's prior epistemic state is characterized by a ranking function ρ (on a field over ModL). That function determines the agent's prior belief set B, and so there is no need to specify B in addition to ρ. If the agent receives new information in form of a proposition A, as AGM belief revision theory has it, there are infinitely many ways to update her ranking function that all give rise to the same new belief set B ∗ A. Let n be an arbitrary positive number in N∪{∞}. Then Spohn conditionalization on the partition {A, W \ A} with n > 0 as new rank for W \ A (and consequently 0 as new rank for A), ρn′(W \ A) = n, determines a new ranking function ρn′ that induces a belief set Bn′. We have for any two positive numbers m, n in N∪{∞}: Bm′ = Bn′ = B ∗ A, where the latter is the belief set described two paragraphs ago.
Plain conditionalization is the special case of Spohn conditionalization with ∞ as new rank for W \ A. The new ranking function obtained in this way is ρ′∞ = ρ(·|A), and the belief set it induces is the same B ∗ A as before. But once the epistemic agent assigns rank ∞ to W \ A, she can never get rid of A again (in the sense that the only information that would allow her to give up her belief that A is to become certain that A is false, i.e., assign rank ∞ to A; that in turn would make her epistemic state collapse in the sense of turning it into the tabula rasa ranking that is agnostic with respect to all contingent propositions). Just as in probabilism you are stuck with A once you assign it probability 1, so you are basically stuck with A once you assign its negation rank ∞. As we have seen, AGM belief revision theory is compatible with always updating in this way. That explains why it cannot handle iterated belief revision. To rule out this behavior one has to impose further constraints on entrenchment orderings. Boutilier (1996) as well as Darwiche & Pearl (1997) do so by postulating constraints compatible with, but not yet implying ranking theory. Hild & Spohn (2008) argue that one really has to go all the way to ranking functions. Stalnaker (2009) critically discusses these approaches and argues that one needs to distinguish different kinds of information, including meta-information about the agent's own beliefs and revision policies as well as about the sources of her information.
For a discussion of belief revision theory in the setting of possibility theory see Dubois & Prade (2009).
3.5 Nonmonotonic Reasoning
Let us finally turn to nonmonotonic reasoning (for more information see the entry on non-monotonic logic). A premise β classically entails a conclusion γ, β ⊢ γ, just in case γ is true in every model or truth value assignment in which β is true. The classical consequence relation ⊢ (conceived of as a relation between two sentences rather than as a relation between a set of sentences, the premises, and a sentence, the conclusion) is non-ampliative in the sense that the conclusion of a classically valid argument does not convey information that goes beyond the information contained in the premise.
⊢ has the following monotonicity property. For any sentences α, β, γ in L:
If α ⊢ γ, then α∧β ⊢ γ
That is, if γ follows from α, then γ follows from any sentence α∧β that is at least as logically strong as α. However, everyday reasoning is often ampliative. When Sophia sees the thermometer at 85° Fahrenheit she infers that it is not too cold to wear her sundress. If Sophia additionally sees that the thermometer is placed above the oven where she is boiling her pasta, she will not infer that any more. Nonmonotonic reasoning is the study of reasonable consequence relations which violate monotonicity (Gabbay 1985, Kraus & Lehmann & Magidor 1990, Makinson 1989; for an overview see Makinson 1994).
For a fixed set of background beliefs B, the revision operators
∗ from the previous paragraphs give rise to nonmonotonic
consequence relations
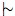 as follows (Makinson & Gärdenfors 1991):
as follows (Makinson & Gärdenfors 1991):
α
Nonmonotonic consequence relations on a language L are supposed to satisfy the following principles from Kraus & Lehmann & Magidor (1990).
| [KLM1] | α
α |
Reflexivity |
| [KLM2] | If
⊢
α ↔ β and α
γ, then β
γ |
Left Logical Equivalence |
| [KLM3] | If
⊢
α → β and γ
α, then γ
β |
Right Weakening |
| [KLM4] | If α∧β
γ and α
β, then α
γ |
Cut |
| [KLM5] | If α
β and α
γ, then α∧β
γ |
Cautious Monotonicity |
| [KLM6] | If α
γ and β
γ, then α∨β
γ |
Or |
The standard interpretation of a nonmonotonic consequence relation
is
“If …, normally …”. Normality among worlds
is spelt out in terms of preferential models <S, l,
≼>
for L, where S is a set of states, and
l: S → ModL is a function
that assigns each state s in S its
world l(s) in ModL. The
abnormality relation
≼
is a strict partial order on ModL that
satisfies a certain smoothness condition. For our purposes it
suffices to note that the order among the worlds that is induced by a
pointwise ranking function is such an abnormality relation. Given a
preferential model <S, l,
≼>
we can define a nonmonotonic consequence relation
as follows. Let
α
be the set of states in whose worlds α is true, i.e.,
α =
{s ∈ S: l(s)
⊨ α}, and define
α
That is, α
β holds just in case β is true in the least abnormal among
the α-worlds. Then one can prove the following representation
theorem:
Theorem 2:
Let L be a language, let B ⊆ L be a set of sentences, and let α ∈ L be a sentence. Each preferential model <S, l, > for L induces a nonmonotonic consequence relation
Whereas the classical consequence relation preserves truth in all logically possible worlds, nonmonotonic consequence relations preserve truth in all least abnormal worlds. For a different semantics in terms of inhibition nets see Leitgeb (2004). Makinson (2009) contains an excellent presentation of ideas underlying nonmonotonic reasoning and its relation to degrees of belief.
Bibliography
- Alchourrón, Carlos E. & Gärdenfors, Peter & Makinson, David (1985), “On the Logic of Theory Change: Partial Meet Contraction and Revision Functions”. Journal of Symbolic Logic, 50: 510-530.
- Armendt, Brad (1980), “Is There a Dutch Book Argument for Probability Kinematics?” Philosophy of Science, 47: 583-588.
- ––– (1993), “Dutch Book, Additivity, and Utility Theory”. Philosophical Topics, 21: 1-20.
- Arntzenius, Frank (2003), “Some Problems for Conditionalization and Reflection”. Journal of Philosophy, 100: 356-371.
- Boutilier, Craig (1996), “Iterated Revision and Minimal Change of Belief”. Journal of Philosophical Logic, 25: 263-305.
- Bovens, Luc & Hartmann, Stephan (2003), Bayesian Epistemology. Oxford: Oxford University Press.
- Carnap, Rudolf (1962), Logical Foundations of Probability. 2nd ed. Chicago: University of Chicago Press.
- Christensen, David (1996), “Dutch-Book Arguments Depragmatized: Epistemic Consistency for Partial Believers”. Journal of Philosophy, 93: 450-479.
- ––– (2004), Putting Logic in Its Place. Formal Constraints on Rational Belief. Oxford: Oxford University Press.
- Cox, Richard T. (1946), “Probability, Frequency, and Reasonable Expectation”. American Journal of Physics, 14: 1-13.
- Darwiche, Adnan & Pearl, Judea (1997), “On the Logic of Iterated Belief Revision”. Artificial Intelligence, 89: 1-29.
- Dempster, Arthur P. (1968), “A Generalization of Bayesian Inference”. Journal of the Royal Statistical Society. Series B (Methodological), 30: 205-247.
- Dubois, Didier & Prade, Henri (1988), Possibility Theory. An Approach to Computerized Processing of Uncertainty. New York: Plenum.
- ––– (2009), “Accepted Beliefs, Revision, and Bipolarity in the Possibilistic Framework”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Egan, Andy (2006), “Secondary Qualities and Self-Location”. Philosophy and Phenomenological Research, 72: 97-119.
- Elga, Adam (2000), “Self-Locating Belief and the Sleeping Beauty Problem”. Analysis, 60: 143-147.
- Eriksson, Lina & Hájek, Alan (2007), “What Are Degrees of Belief?” Studia Logica, 86: 183-213.
- Field, Hartry (1978), “A Note on Jeffrey Conditionalization”. Philosophy of Science, 45: 361-367.
- Fitelson, Branden (2003), “A Probabilistic Theory of Coherence”. Analysis, 63: 194-199.
- Foley, Richard (1992), “The Epistemology of Belief and the Epistemology of Degrees of Belief”. American Philosophical Quarterly, 29: 111-121.
- ––– (2009), “Belief, Degrees of Belief, and the Lockean Thesis”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Frankish, Keith (2004), Mind and Supermind. Cambridge: Cambridge University Press.
- ––– (2009), “Partial Belief and Flat-Out Belief”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Gabbay, Dov M. (1985), “Theoretical Foundations for Non-Monotonic Reasoning in Expert Systems”. In K.R. Apt (ed.), Logics and Models of Concurrent Systems. NATO ASI Series 13. Berlin: Springer, 439-457.
- Garber, Daniel (1983), “Old Evidence and Logical Omniscience in Bayesian Confirmation Theory”. In J. Earman (ed.), Testing Scientific Theories. Minnesota Studies in the Philosophy of Science 10. Minneapolis: University of Minnesota Press, 99-131.
- Gärdenfors, Peter (1988), Knowledge in Flux. Modeling the Dynamics of Epistemic States. Cambridge, MA: MIT Press.
- Gärdenfors, Peter & Rott, Hans (1995), “Belief Revision”. In D.M. Gabbay & C.J. Hogger & J.A. Robinson (eds.), Handbook of Logic in Artificial Intelligence and Logic Programming. Vol. 4. Epistemic and Temporal Reasoning. Oxford: Clarendon Press, 35-132.
- Giang, Phan H. & Shenoy, Prakash P. (2000), “A Qualitative Linear Utility Theory for Spohn's Theory of Epistemic Beliefs”. In C. Boutilier & M. Goldszmidt (eds.), Uncertainty in Artificial Intelligence. Vol. 16. San Francisco: Morgan Kaufmann, 220-229.
- Glymour, Clark (1980), Theory and Evidence. Princeton: Princeton University Press.
- Greaves, Hilary & Wallace, David (2006), “Justifying Conditionalization: Conditionalization Maximizes Expected Epistemic Utility”. Mind, 115: 607-632.
- Haenni, Rolf (2009), “Non-Additive Degrees of Belief”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Haenni, Rolf & Lehmann, Norbert (2003), “Probabilistic Argumentation Systems: A New Perspective on Dempster-Shafer Theory”. International Journal of Intelligent Systems, 18: 93-106.
- Hájek, Alan (1998), “Agnosticism Meets Bayesianism”. Analysis, 58: 199-206.
- ––– (2003), “What Conditional Probability Could Not Be”. Synthese, 137: 273-323.
- ––– (2005), “Scotching Dutch Books?” Philosophical Perspectives, 19: 139-151.
- ––– (2008), “Arguments for – or against – Probabilism?” British Journal for the Philosophy of Science, 59 (4). Reprinted in F. Huber & C. Schmidt-Petri (eds., 2009), Degrees of Belief. Dordrecht: Springer.
- Halpern, Joseph Y. (2003), Reasoning about Uncertainty. Cambridge, MA: MIT Press.
- Hansson, Sven Ove (1999), “A Survey of Non-Prioritized Belief Revision”. Erkenntnis, 50: 413-427.
- Hawthorne, James (2009), “The Lockean Thesis and the Logic of Belief”. In F. Huber & C. Schmidt-Petri (ed.), Degrees of Belief. Dordrecht: Springer.
- Hawthorne, James & Bovens, Luc (1999), “The Preface, the Lottery, and the Logic of Belief”. Mind, 108: 241-264.
- Hawthorne, John (2004), Knowledge and Lotteries. Oxford: Oxford University Press.
- Hempel, Carl Gustav (1962), “Deductive-Nomological vs. Statistical Explanation”. In H. Feigl & G. Maxwell (eds.), Scientific Explanation, Space and Time. Minnesota Studies in the Philosophy of Science 3. Minneapolis: University of Minnesota Press, 98-169.
- Hendricks, Vincent F. (2006), Mainstream and Formal Epistemology. New York: Cambridge University Press.
- Hendricks, Vincent F. & Symons, John (eds.), Formal Philosophy. Copenhagen: Automatic Press, 2005.
- Hild, Matthias & Spohn, Wolfgang (2008), “The Measurement of Ranks and the Laws of Iterated Contraction”. Artificial Intelligence, 172: 1195-1218.
- Hintikka, Jaakko (1961), Knowledge and Belief. An Introduction to the Logic of the Two Notions. Ithaca, NY: Cornell University Press. Reissued as J. Hintikka (2005), Knowledge and Belief. An Introduction to the Logic of the Two Notions. Prepared by V.F. Hendricks & J. Symons. London: King's College Publications.
- Huber, Franz (2006), “Ranking Functions and Rankings on Languages”. Artificial Intelligence, 170: 462-471.
- ––– (2007b), “The Consistency Argument for Ranking Functions”. Studia Logica, 86: 299-329.
- ––– (2009), “Belief and Degrees of Belief”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Jeffrey, Richard C. (1970), “Dracula Meets Wolfman: Acceptance vs. Partial Belief”. In M. Swain (ed.), Induction, Acceptance, and Rational Belief. Dordrecht: D. Reidel, 157-185.
- ––– (1983a), The Logic of Decision. 2nd ed. Chicago: University of Chicago Press.
- ––– (1983b), “Bayesianism with a Human Face”. In J. Earman (ed.), Testing Scientific Theories. Minnesota Studies in the Philosophy of Science 10. Minneapolis: University of Minnesota Press, 133-156.
- ––– (2004), Subjective Probability. The Real Thing. Cambridge: Cambridge University Press.
- Joyce, James M. (1998), “A Nonpragmatic Vindication of Probabilism”. Philosophy of Science, 65: 575-603.
- ––– (1999), The Foundations of Causal Decision Theory. Cambridge: Cambridge University Press.
- ––– (2009), “Accuracy and Coherence: Prospects for an Alethic Epistemology of Partial Belief”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Kahneman, Daniel & Slovic, Paul & Tversky, Amos, eds., (1982), Judgment Under Uncertainty. Heuristics and Biases. Cambridge: Cambridge University Press.
- Kaplan, Mark (1996), Decision Theory as Philosophy. Cambridge: Cambridge University Press.
- Kneale, William C. (1949), Probability and Induction. Oxford: Clarendon Press.
- Kolmogorov, Andrej N. (1956), Foundations of the Theory of Probability. 2nd ed. New York: Chelsea Publishing Company.
- Krantz, David H. & Luce, Duncan R. & Suppes, Patrick & Tversky, Amos (1971), Foundations of Measurement. Vol. I. New York: Academic Press.
- Kraus, Sarit & Lehmann, Daniel & Magidor, Menachem (1990), “Nonmonotonic Reasoning, Preferential Models, and Cumulative Logics”. Artificial Intelligence, 40: 167-207.
- Kripke, Saul (1979), “A Puzzle About Belief”. In A. Margalit (ed.), Meaning and Use. Dordrecht: D. Reidel, 239-283.
- Kvanvig, Jonathan L. (1994), “A Critique of van Fraassen's Voluntaristic Epistemology”. Synthese, 98: 325-348.
- Kyburg, Henry E. Jr. (1961), Probability and the Logic of Rational Belief. Middletown, CT: Wesleyan University Press.
- Kyburg, Henry E. Jr. & Teng, Choh Man (2001), Uncertain Inference. Cambridge: Cambridge University Press.
- Leitgeb, Hannes (2004), Inference on the Low Level. An Investigation into Deduction, Nonmonotonic Reasoning, and the Philosophy of Cognition. Dordrecht: Kluwer.
- Levi, Isaac (1967a), Gambling With Truth. An Essay on Induction and the Aims of Science. New York: Knopf.
- ––– (1967b), “Probability Kinematics”. British Journal for the Philosophy of Science, 18: 197-209.
- ––– (1978), “Dissonance and Consistency according to Shackle and Shafer”. PSA: Proceedings of the Biennial Meeting od the Philosophy of Science Association, Vol. 1978, Vol. Two: Symposia and Invited Papers, 466-477.
- ––– (1980), The Enterprise of Knowledge. Cambridge, MA: MIT Press.
- Lewis, David K. (1979), “Attitudes De Dicto and De Se”. The Philosophical Review, 88: 513-543. Reprinted with postscripts in D. Lewis (1983), Philosophical Papers. Vol. I. Oxford: Oxford University Press, 133-159.
- ––– (1980), “A Subjectivist's Guide to Objective Chance”. In R.C. Jeffrey (ed.), Studies in Inductive Logic and Probability. Vol. II. Berkeley: University of Berkeley Press, 263-293. Reprinted with postscripts in D. Lewis (1986), Philosophical Papers. Vol. II. Oxford: Oxford University Press, 83-132.
- ––– (1986), On the Plurality of Worlds. Oxford: Blackwell.
- ––– (1999), “Why Conditionalize?” In D. Lewis (1999), Papers in Metaphysics and Epistemology. Cambridge: Cambridge University Press, 403-407.
- ––– (2001), “Sleeping Beauty: Reply to Elga”. Analysis, 61: 171-176.
- Locke, John (1690/1975), An Essay Concerning Human Understanding. Oxford: Clarendon Press.
- Maher, Patrick (2002), “Joyce's Argument for Probabilism”. Philosophy of Science, 69: 73-81.
- ––– (2006), “Review of David Christensen, Putting Logic in Its Place. Formal Constraints on Rational Belief”. Notre Dame Journal of Formal Logic, 47: 133-149.
- Makinson, David (1965), “The Paradox of the Preface”. Analysis, 25: 205-207.
- ––– (1989), “General Theory of Cumulative Inference”. In M. Reinfrank & J. de Kleer & M.L. Ginsberg & E. Sandewall (eds.), Non-Monotonic Reasoning. Lecture Notes in Artificial Intelligence 346. Berlin: Springer, 1-18.
- ––– (1994), “General Patterns in Nonmonotonic Reasoning”. In D.M. Gabbay & C.J. Hogger & J.A. Robinson (eds.), Handbook of Logic in Artificial Intelligence and Logic Programming. Vol. 3. Nonmonotonic Reasoning and Uncertain Reasoning. Oxford: Clarendon Press, 35-110.
- ––– (2009), “Levels of Belief in Nonmonotonic Reasoning”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Makinson, David & Gärdenfors, Peter (1991), “Relations between the Logic of Theory Change and Nonmonotonic Logic”. A. Fuhrmann & M. Morreau (eds.), The Logic of Theory Change. Berlin: Springer, 185-205.
- Niiniluoto, Ilkka (1983), “Novel Facts and Bayesianism”. British Journal for the Philosophy of Science, 34: 375-379.
- Olsson, Erik (2005), Against Coherence. Truth, Probability, and Justification. Oxford: Oxford University Press.
- Paris, Jeff B. (1994), The Uncertain Reasoner's Companion - A Mathematical Perspective. Cambridge Tracts in Theoretical Computer Science, 39: Cambridge: Cambridge University Press.
- Ramsey, Frank P. (1926), “Truth and Probability”. In F.P. Ramsey (1931), The Foundations of Mathematics and Other Logical Essays. Ed. by R.B. Braithwaite. London: Kegan, Paul, Trench, Trubner & Co., New York: Harcourt, Brace and Company, 156-198.
- Rott, Hans (2001), Change, Choice, and Inference. A Study of Belief Revision and Nonmonotonic Reasoning. Oxford: Oxford University Press.
- ––– (2009), “Degrees All the Way Down: Beliefs, Non-Beliefs, Disbeliefs”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Savage, Leonard J. (1972). The Foundations of Statistics. 2nd ed. New York: Dover.
- Shackle, George L.S. (1949), Expectation in Economics. Cambridge: Cambridge University Press.
- ––– (1969), Decision, Order, and Time. 2nd ed. Cambridge: Cambridge University Press.
- Shafer, Glenn (1976), A Mathematical Theory of Evidence. Princteton, NJ: Princeton University Press.
- Shenoy, Prakash P. (1991), “On Spohn's Rule for Revision of Beliefs”. International Journal for Approximate Reasoning, 5: 149-181.
- Skyrms, Brian (1984), Pragmatism and Empiricism. Yale: Yale University Press.
- ––– (1987), “Dynamic Coherence and Probability Kinematics”. Philosophy of Science, 54: 1-20.
- ––– (2006), “Diachronic Coherence and Radical Probabilism”. Philosophy of Science, 73: 959-968. Reprinted in F. Huber & C. Schmidt-Petri (eds., 2009), Degrees of Belief. Dordrecht: Springer, forthcoming.
- Smets, Philippe (2002), “Showing Why Measures of Quantified Beliefs are Belief Functions”. In B. Bouchon & L. Foulloy & R.R. Yager (eds.), Intelligent Systems for Information Processing: From Representation to Applications. Amsterdam: Elsevier, 265-276.
- Smets, Philippe & Kennes, Robert (1994), “The Transferable Belief Model”. Artifical Intelligence, 66: 191-234.
- Spohn, Wolfgang (1988), “Ordinal Conditional Functions: A Dynamic Theory of Epistemic States”. In W.L. Harper & B. Skyrms (eds.), Causation in Decision, Belief Change, and Statistics II. Dordrecht: Kluwer, 105-134.
- ––– (1990), “A General Non-Probabilistic Theory of Inductive Reasoning”. In R.D. Shachter & T.S. Levitt & J. Lemmer & L.N. Kanal (eds.), Uncertainty in Artificial Intelligence 4. Amsterdam: North-Holland, 149-158.
- ––– (1994), “On the Properties of Conditional Independence”. In P. Humphreys (ed.), Patrick Suppes. Scientific Philosopher. Vol. 1. Probability and Probabilistic Causality. Dordrecht: Kluwer, 173-194.
- ––– (2009), “A Survey of Ranking Theory”. In F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief. Dordrecht: Springer.
- Stalnaker, Robert C. (1996), “Knowledge, Belief, and Counterfactual Reasoning in Games”. Economics and Philosophy, 12: 133-162.
- ––– (2003), Ways a World Might Be. Oxford: Oxford University Press.
- ––– (2009), “Iterated Belief Revision”. Erkenntnis, 70 (1).
- Teller, Paul (1973), “Conditionalization and Observation”. Synthese, 26: 218-258.
- van Fraassen, Bas C. (1989), Laws and Symmetry. Oxford: Oxford University Press.
- ––– (1990), “Figures in a Probability Landscape”. In J.M. Dunn & A. Gupta (eds.), Truth or Consequences. Dordrecht: Kluwer, 345-356.
- ––– (1995), “Belief and the Problem of Ulysses and the Sirens”. Philosophical Studies, 77: 7-37.
- Walley, Peter (1991), Statistical Reasoning With Imprecise Probabilities. New York: Chapman and Hall.
- Weatherson, Brian (2005), “Can We Do Without Pragmatic Encroachment?” Philosophical Perspectives, 19: 417-443.
- ––– (2007), “The Bayesian and the Dogmatist”. Proceedings of the Aristotelian Society, 107: 169-185.
- Williamson, Timothy (1994), Vagueness. New York: Routledge.
- Zadeh, Lotfi A. (1978), “Fuzzy Sets as a Basis for a Theory of Possibility”. Fuzzy Sets and Systems, 1: 3-28.
Other Internet Resources
- Field, Hartry (forthcoming), “Vagueness, Partial Belief, and Logic”. In G. Ostertag (ed.), Meanings and Other Things: Essays on Stephen Schiffer.
- Huber, Franz (2007a), Confirmation and Induction. In J. Fieser & B. Dowden (eds.), The Internet Encyclopedia of Philosophy.
- Pryor, James (manuscript), “Uncertainty and Undermining”, online preprint.
- Roorda, Jonathan (1995), Revenge of Wolfman: A Probabilistic Explication of Full Belief, (PDF), unpublished manuscript.
- Titelbaum, Mike (forthcoming), “The Relevance of Self-Locating Beliefs”, The Philosophical Review. [Preprint available from author].
- Weisberg, Jonathan (forthcoming), “Varieties of Bayesianism”. In D.M. Gabbay & S. Hartmann & J. Woods (eds.), Handbook of the History of Logic. Vol. 10: Inductive Logic. Amsterdam/New York: Elsevier.
Related Entries
epistemology | logic: epistemic | logic: non-monotonic | possible worlds | probability, interpretations of | propositions: structured | vagueness
Acknowledgments
I am grateful to Branden Fitelson, Alan Hájek, and Wolfgang Spohn for their comments and suggestions. I have used material from Huber (2009) for this entry.